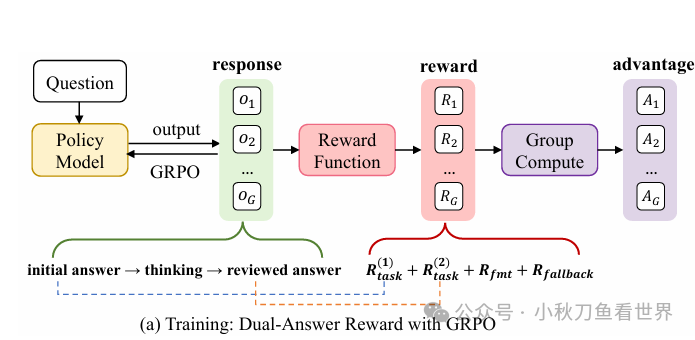
1. 背景介绍
这篇论文的核心就是 "answer → think → answer"。
一次思考,两次回答。以往的推理模型都是在回答之前进行推理,然后输出答案。这次我们将推理模型和非推理模型结合起来,先让模型回答一个答案,如果这个答案置信度比较高,那么直接输出这个答案。否则,我们再进行推理,再输出改进以后的答案。
这里我们这么做的目的是要回答一个问题:模型进行推理是必要的吗?
显然对于简单的问题,模型自己依靠自身的知识就能很好的回答,我们无需进行推理。只有那些复杂的问题,我们才需要引入思维链来推理。
架构图如下:
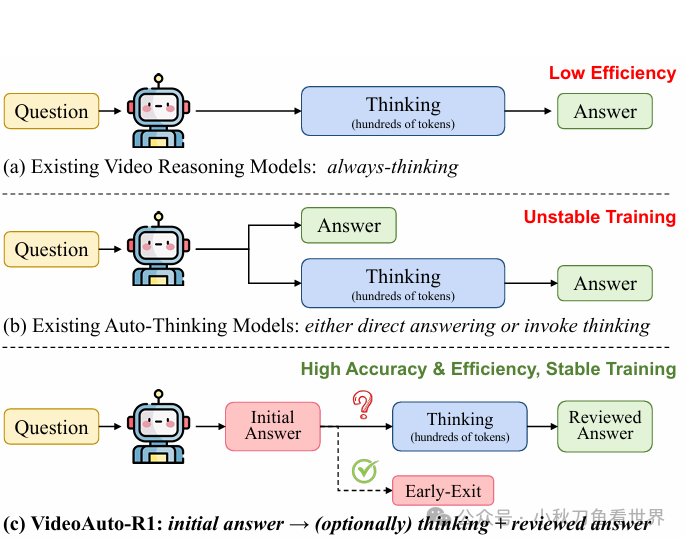
2. 训练过程
设计了一个双答案奖励的机制。具体来说就是提取前后两次的答案,然后这两次答案分配的权重是不一样的。如果两次答案都是对的,那么第二次的答案的权重会高于前一次。如果第一次对,第二次不对,我们就要惩罚模型。
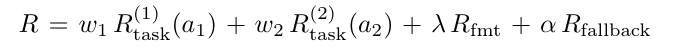
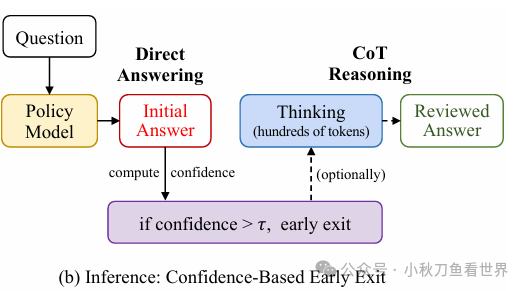
推理的时候,设计了一个早停机制。具体来说,我们要先计算一下模型输出的置信度,如果置信度很高,超过一定的阈值,我们就直接输出答案。否则我们继续进行推理。
置信度的计算比较直接,使用长度归一化的置信度计算:
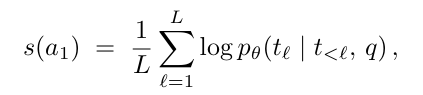
整体训练与推理过程图: