AP2O-Coder
论文标题:AP2O-Coder: Adaptively Progressive Preference Optimization for Reducing Compilation and Runtime Errors in LLM-Generated Code
当前离线偏好优化方法(如 DPO 等)在 LLM 代码纠错任务中面临三大核心挑战:
现有方法的核心挑战与AP2O-Coder的针对性设计
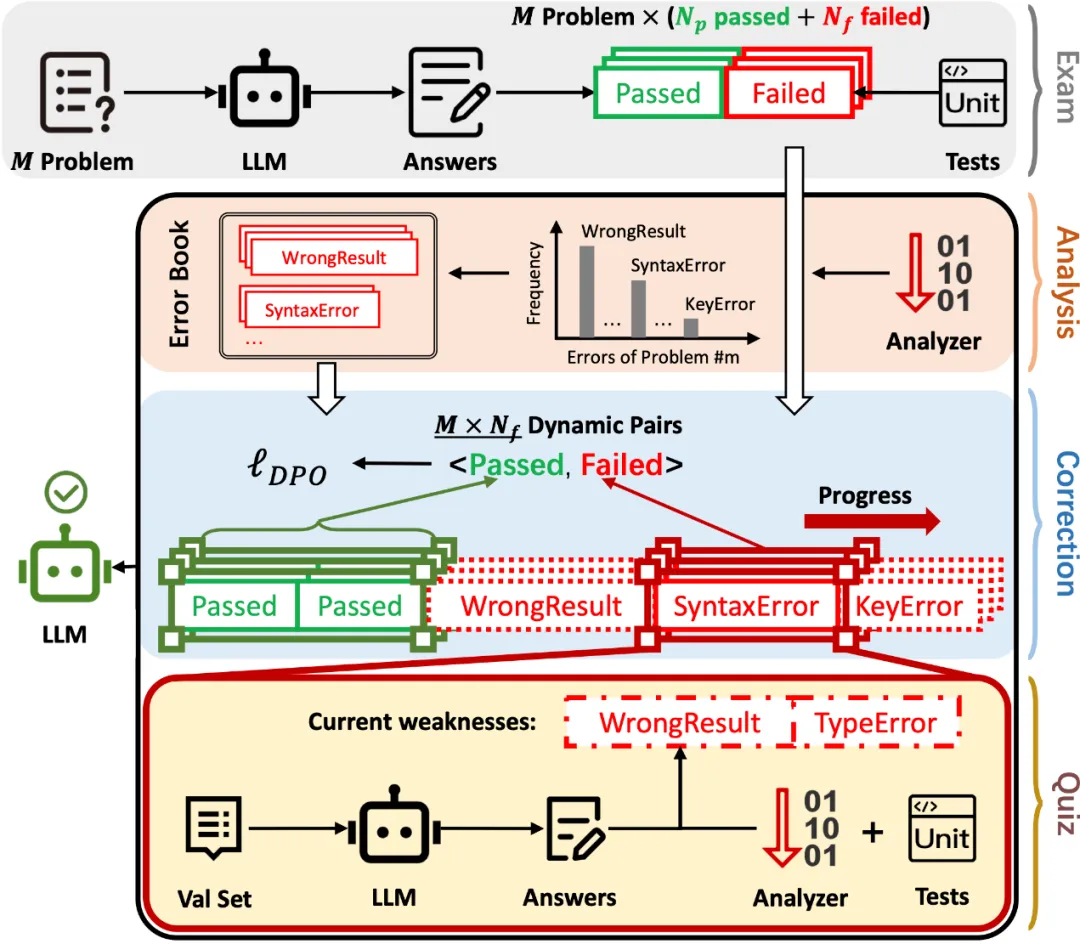
图 1:AP2O-Coder 整体架构图
- 错误类型感知缺失:仅依赖单元测试的二元反馈信号,无法知晓类型错误(如 KeyError、ValueError 等),导致模型难以定位错误原因;
- 训练聚焦性不足:训练数据采用随机打乱的方式批量输入,模型需在多种错误类型间频繁切换适应,纠错学习的针对性不强;
- 动态适配能力薄弱:静态构建的训练集无法匹配模型训练过程中不断变化的能力短板,易引发灾难性遗忘或训练资源浪费。
为应对上述挑战,AP2O-Coder 借鉴人类按题型进行的「错题整理 - 专题突破 - 定期复盘」的学习模式,构建了包含四大核心模块的优化框架,旨在实现错误信息的深度利用与模型能力的动态适配。
AP2O-Coder的核心技术框架与工作机制
1. 代码生成评估(Exam)
为全面掌握目标模型的初始能力边界,该模块让 LLM 在 M 个编程任务上生成 N 个候选答案(采用温度系数 1.0 的设置以充分探索能力范围),通过配套的单元测试获取每个答案的「通过 / 失败」标签,形成初始训练数据集,为后续错误分析提供基础。
2. 错误诊断分析(Analysis)
借助编程语言专用分析工具(如 Python 解释器)对所有失败答案进行结构化解析,标注具体错误类型并统计各类错误的出现频率,按错误题型构建结构化的「错题本」。该过程实现了从二元反馈到精细化错误信息的转化,为针对性优化提供数据支撑。
3. 渐进式偏好优化(Correction)
基于错题本,设计差异化的优化顺序:对于小参数模型(如 0.5B)采用「低频错误 -> 高频错误」(L2H)的优化路径,对于大参数模型(如 34B)采用「高频错误 -> 低频错误」(H2L)的优化策略。
通过构建 DPO 滑动窗口,逐步聚焦各类错误类型,一个题型一个题型地纠错,生成有序的偏好数据对。在这些数据对中,Prompt 作为输入,正确的回答(随机获得)作为 Positive 样本,错误类型为 E 的错误回答作为 Negative 样本,使模型能够分阶段集中优化特定类型错误。
- 对于 Qwen2.5-Coder,小参数模型(≤ 3B)采用「低频错误 -> 高频错误」的优化顺序更具优势,这一策略可避免模型因能力有限而陷入高频常见错误的学习困境,而让小模型一开始能看到不同种类的错误,跳出局部最优;
- 大参数模型(≥ 7B)采用「高频错误 -> 低频错误」的顺序效果更优,能够充分发挥其强学习能力,快速实现整体错误率的下降。这一发现为不同规模 LLM 的代码优化提供了针对性参考。
4. 自适应错误回放(Quiz)
为适配模型训练过程中的能力变化,该模块定期在一个小验证集上评估模型性能,实时捕捉当前阶段的高频错误类型,找出模型依旧犯错的题型,将其对应的失败答案重新纳入训练流程。通过动态调整训练数据分布,确保模型始终聚焦于当前的能力短板,有效缓解灾难性遗忘问题。