问题背景
大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?
Paper: https://arxiv.org/abs/2511.08043
Code: https://github.com/zhaoxlpku/DynaAct
系统实现层面,团队开源了基于 vLLM 的高性能 MCTS 框架。
DynaAct 提出以 Action Space Optimization 为核心的 TTS 范式:在每一步推理中动态构建可选动作集合,并通过学习算法从中选择最优动作,从而让推理路径更高效、更具结构化。
为什么是 Action Space 优化?
当前主流 TTS 方法通过「更长的思维链」来提升性能,但随之而来的,是搜索空间爆炸与冗余思考。团队认为,推理效率的瓶颈并不在「算得不够多」,而在「选得不够好」。
DynaAct 将推理过程类比为决策序列:每一步的关键不是「生成什么」,而是「选择什么去执行」。
因此,它聚焦于如何自动学习、动态构建每一步推理的动作空间,并提出两条核心原则:
- 数据驱动——动作候选从真实推理数据中学习,而非人工规则生成;
- 完备且紧凑——既覆盖潜在解,又避免冗余。
方法:Submodular Optimization × MCTS
1. 核心问题:为什么要选「动作子集」?
超市篮子类比:
想象你在一个巨大的超市里(这就像机器人的整个动作空间,里面有成千上万种动作),你需要买一篮子东西回家做饭(完成任务)。
- 传统方法:可能会把超市里每一个商品都拿起来看一遍,计算它对这顿饭有没有用。如果超市有 1 万种商品,这太慢了。
- DynaAct 的方法:它不想看所有商品,它只想快速挑出一个「精选篮子」(比如只挑 10 个最有代表性的动作)。只要在这个精选篮子里找,就能解决大问题。
核心思想转化:DynaAct 不再去纠结怎么微调每一个动作,而是变成了一个「挑东西进篮子」的问题(集合选择问题)。
2. 什么是子模性(Diminishing Returns)?
DynaAct 用了一种叫「子模优化」的技术,其实就是「边际收益递减」。
生活例子:苹果收益
你买第 1 个苹果,非常开心(收益 +10)。
你买第 2 个苹果,还是挺开心,但没第一个那么想吃了(收益 +8)。
当你已经有 100 个苹果时,再给你第 101 个苹果,你几乎没感觉了(收益 +0.1)。
在 DynaAct 中:
这就是说,你要挑的那个「动作篮子」,如果你一直往里面加相似的动作,带来的好处会越来越少。利用这个性质,我们就可以用贪心算法(每次只拿当前看起来最好的那一个),快速填满篮子,而不需要把所有组合都试一遍。这就保证了速度快(线性复杂度)。
3. 最关键的部分:Utility(效用)和 Diversity(多样性)
挑进篮子的动作,必须满足两个条件才算好。
(1) Utility(效用):必须是有用的
- 定义:度量动作空间与当前状态的相似度。
- 通俗解释:「这东西得是我现在能用的。」
- 例子:如果你现在的状态是「切菜」,那么「拿刀」、「按住菜」这些动作的效用就很高;而「跳舞」、「睡觉」这些动作的效用就很低。
- 目的:确保篮子里的动作能帮你解决眼前的困难。
(2) Diversity(多样性):必须是不重复的
- 定义:刻画动作空间中动作的冗余度。
- 通俗解释:「篮子里的东西别太重样。」
- 例子:
- 如果不考虑多样性:你的篮子里可能装了 10 把不同颜色的刀。虽然它们都有用(Utility 高),但这没必要,你只需要一把刀。
- 考虑多样性:你的篮子里应该有一把刀、一个菜板、一个锅。虽然它们也是工具,但它们功能不同,互补性强。
- 目的:用最少的动作数量,覆盖尽可能多的可能性,避免浪费计算资源去处理一堆差不多的动作。
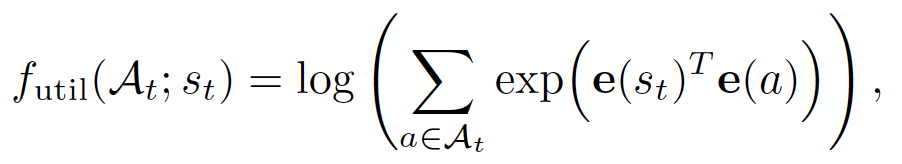
「定义子模函数」本质上等价于「学习 Embedding」
Embedding
Embedding(嵌入) 就是把这些原本没法比较的东西,变成一组「有意义的数字坐标(向量)」。
通俗例子:商品标签
想象给超市里的商品和你的需求打标签(这就是 Embedding 过程)。
- 状态(番茄炒蛋): [红色需求: 0.8, 蛋白质需求: 0.9, 切割需求: 0.5]
- 动作 A(拿西红柿): [红色属性: 0.9, 蛋白质属性: 0.1, 切割属性: 0.0]
- 动作 B(拿鸡蛋): [红色属性: 0.1, 蛋白质属性: 0.9, 切割属性: 0.0]
- 动作 C(跳舞): [红色属性: 0.0, 蛋白质属性: 0.0, 切割属性: 0.0]
Q-learning
Q-learning(一种强化学习算法)充当「阅卷老师」。
流程拆解:
- DynaAct(学生):根据当前的 Embedding,挑了一个动作篮子(比如选了“跳舞”)。
- 环境(现实):机器人去执行“跳舞”。
- 结果(Reward):饭没做成,饿肚子了。回报 = -100。
- Q-learning(老师):拿着这个 -100 分的试卷告诉学生:“你选错了!这次选的动作导致了坏结果。”
- 反向传播(修正):
- 学生就会想:“既然结果很差,说明我当初挑那个篮子挑错了。”
- “是因为我觉得‘跳舞’和‘做饭’很像(Embedding 距离近)。”
- “所以我得改 Embedding! 把‘跳舞’和‘做饭’的距离拉远!”

DynaAct 算法核心逻辑伪代码
总结
DynaAct 证明了:TTS 的未来,不在更多计算,而在更聪明的搜索。
团队计划进一步探索
- 将 Dynamic Action Space 扩展到 multi-agent 规划场景;
- 将子模优化与强化学习结合,学习端到端的自适应推理策略;
>> DynaAct用子模优化快速“缩小范围”,用强化学习“缩小范围”的标准是否正确,最终通过端到端学习让机器人自动学会“在什么状态下该选哪些动作”。
- 推出更高效的 MCTS 工具包,服务开源社区。