论文标题:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
论文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
1. 动机:为什么要"解耦推理与知识"?
在标准 Transformer 里,"推理"和"背知识"用的是同一套计算路径。
- 对人来说,很多知识检索更像"查表":看到"李白",你几乎是 O(1) 地回忆出"唐朝/诗人/诗仙"。
- 对 Transformer 来说,即使是"李白是诗人"这种静态事实,往往也要靠多层 Attention + FFN 的矩阵乘法把表示"一步步挤出来"。
- 结果:早期层为了"重建大量静态关系"占用了参数容量与推理算力,真正留给复杂推理(尤其是长程依赖与组合推理)的"有效层数"变少。
一句话总结:我们在用"算法"做"查字典"的工作。Engram 试图把这部分工作从主干网络里剥离出来。
2. Engram 是什么?
Engram 的核心想法:在若干 Transformer block 内插入一个"确定性 N-gram 记忆检索模块",把局部、静态、重复出现的依赖关系交给查表,把主干网络的算力更多留给全局建模与推理。
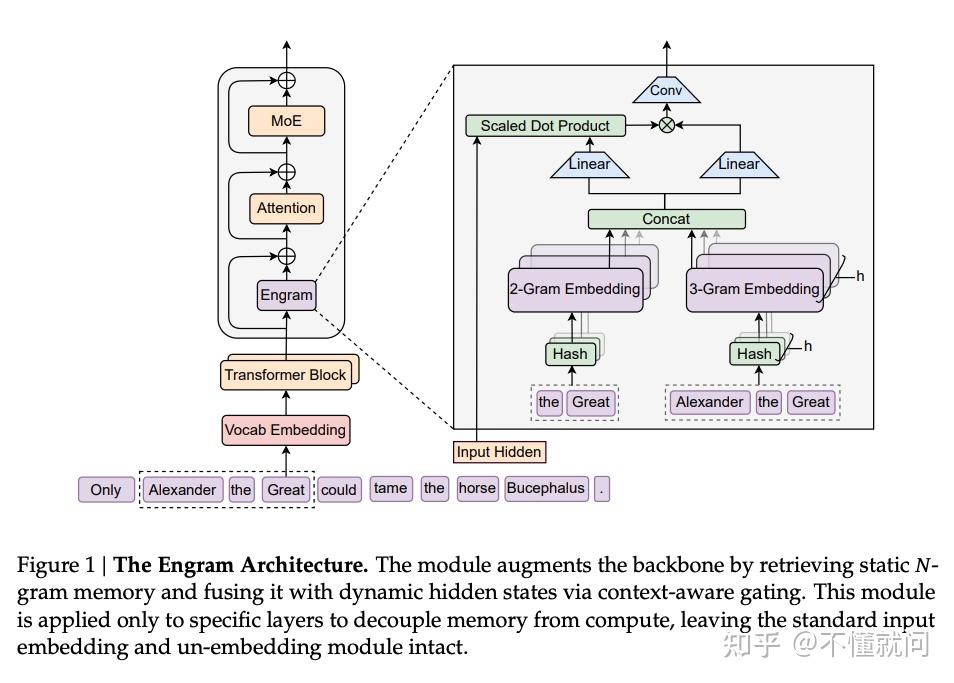
3. 预备知识:N-gram 为什么能成为"记忆地址"?
N-gram 就是滑动窗口下连续的 N 个 token 子序列。例如句子 "Deep learning is amazing":
- 1-gram:Deep / learning / is / amazing
- 2-gram:Deep learning / learning is / is amazing
- 3-gram:Deep learning is / learning is amazing
N-gram 的价值在于:它抓的是"局部上下文"。很多语言现象(专有名词、固定搭配、常见短语、局部语法模式)在局部窗口里就足够稳定,因此可以作为检索静态记忆的 key。
4. 模块细节:Engram 在每个 token 位置做了什么?
4.1 为"记忆"服务的 tokenizer 压缩(Canonical ID)
现实里的 tokenizer 为了可逆,会把 "Apple"(句首)和 "apple"(句中带空格)分成不同 ID;但对"记忆检索"来说它们本质相同。Engram 增加一层映射,把大小写/空格等变体归一到 Canonical ID,减少冗余,让查表更稳定。
4.2 只取 suffix N-gram:保证 causal
在位置 $t$,Engram 只使用以 $x'_t$ 结尾的 suffix N-gram: $g_{t,n} = (x'_{t-n+1}, \dots, x'_t)$
4.3 多头哈希查表:用 K 个地址对抗哈希冲突
直接给所有可能 N-gram 建表会组合爆炸。Engram 用哈希把"无限的 N-gram"映射到"有限的 embedding slot"。由于哈希必然会冲突,它用 K 个不同哈希函数取回 K 份候选向量并拼接,降低"撞车"风险。
4.4 上下文门控(context-aware gating)
Engram 用当前层 hidden state $h_t$ 对候选记忆打分:
4.5 轻量卷积融合
门控后接卷积层做局部整合,让融合更平滑。
为什么需要此操作?
哈希的本质是"乱序"的(Chaos)。
当文本从 "Apple" 变成 "Apply" 时,检索到的地址会天差地别。这种数学上的不连续性对神经网络来说就是"剧烈震荡"。卷积层的作用就是把当前时刻的信息与前后时刻的信息混合,使信号更平滑。
一些补充:
卷积层(Convolutional Layer)的作用:
- 核心机制: 卷积核在输入数据上滑动并做加权求和。
- 在图像中: 提取边缘、纹理、形状。
- 在 NLP/序列中(这里的用法): 通常是 1D 卷积,将当前信息与上下文混合。
比喻:不仅让你盯着当前读的字,还强迫你余光看到前后的字,从而更好理解含义。
池化层(Pooling Layer)的作用:
- 下采样(Downsampling): 缩小尺寸,减少计算量。
- 最大池化: 挑出最强特征,忽略位置微调。
- 平均池化: 模糊细节,保留整体背景。
5. 系统级优化
- 计算与存储解耦: 巨大的 embedding 表可以放在 CPU 内存或 SSD。
- 预取(Prefetching): GPU 算前层时,CPU 提前准备好后层的 N-gram 向量并传输,实现"零开销"外挂。
6. 训练方式
Engram 的 memory 不是预先写死的词典,而是在大规模预训练中端到端学出来的。只有被访问到的 slot 才会收到梯度更新。
7. 稀疏容量分配框架
作者提出了一个公式:$P_{sparse} = P_{tot} - P_{act}$。固定激活参数(FLOPs)的情况下,通过 $\rho$ 参数在 MoE(条件计算)与 Engram(条件存储)之间分配资源。
8. 实验结果
1. 推理收益大: 不仅 LM Loss 低,在代码和数学任务上收益更显著。
2. Scaling Axis: 扩大记忆容量(Engram-40B)能持续提升模型性能,是一条独立的增长曲线。
9. 作者的直觉
9.1 开卷考试类比
- 普通模型: 像裸考学生,进场前 30 分钟在回忆公式。
- Engram 模型: 像带了"小抄"的学生,一分钟内直接拿公式解题。
9.2 证据一:LogitLens
- 在 Engram 模型中,浅层的输出概率分布就已经非常接近最终答案。
- 结论: 知识在前几层就已快速注入。
9.3 证据二:CKA
- 实验发现 Engram 的第 3 层表现最像 Baseline 的第 10 层。
- 结论: 实现了语义上的超前,提升了"有效深度"。
10. 结语
Engram 通过架构层面显式引入"记忆+计算"的解耦,不仅提升了效率,也为未来"更可控的知识编辑"提供了新的可能。