JiT
- 论文标题: Back to Basics: Let Denoising Generative Models Denoise
- 作者: Tianhong Li (黎天鸿), Kaiming He (何恺明)
- 论文地址: https://arxiv.org/abs/2511.13720
- 代码仓库: https://github.com/LTH14/JiT
提出了一种名为 JiT (Just image Transformers) 的方法,倡导让模型回归初心,直接预测干净的图像(x-prediction)。令人惊讶的是,这种看似简单的回归,仅使用一个朴素的、无任何额外组件的 Transformer 架构,就在 ImageNet 等高难度任务上取得了极具竞争力的成果,甚至在某些情况下避免了传统方法的“灾难性失败”。
问题的核心:流形假设
核心论点建立于:
- 干净图像 ($x$):位于这个低维流形上,结构性强。
- 噪声 ($\epsilon$):完全是高维空间中的随机扰动,不遵循任何流形结构。
- 流速 ($v$):作为图像和噪声的组合,同样是“越界”的,处于流形之外。
1. 什么是“流形”(Manifold)?
想象一张揉皱的纸团。虽然这个纸团存在于三维空间里,但纸张本身其实是一个二维平面。在机器学习中,“流形假设”认为:
- 高维空间: 比如一张 $512 \times 512$ 的彩色图像,它在数学上是一个拥有约 78 万个维度的点。
- 低维流形: 尽管维度极高,但“像人脸的图像”或“像猫的图像”只占这个巨大空间中极小极小的一部分。这些有意义的数据点分布在一个规则的、有结构的、低维度的“密封面”上,这个面就是流形。
- “在流形上”: 意味着图像是自然的、有结构的、符合现实世界规律的(即图中的干净图像 $x$)。
2. 什么是“在流形外”(Off-manifold)?
“在流形外”指的就是那些不符合数据内在规律、随机分布在高维空间“空旷地带”的部分。
- 噪声 ($\epsilon$): 纯噪声是完全随机的。它没有任何结构,不遵循任何物理或语义规律。它就像是离开了纸张表面的空气,
散落在三维空间里的任何地方。因此,噪声是典型的“流形外”物体。 - 流速 ($v$): 在流式匹配模型中,流速是指
从噪声点向干净图像点移动的方向向量。因为它的一头连接着“流形外”的噪声,所以这个向量本身也处于流形之外,或者说它代表了一种“跨界”的路径。
参考图:
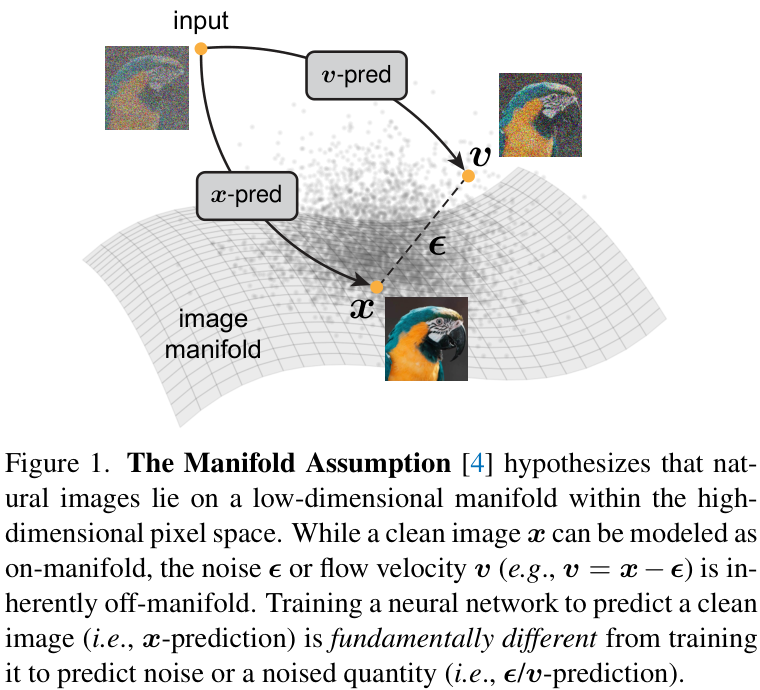
x 预测 vs. $\epsilon/v$ 预测:为何差异如此之大?
扩散模型的工作流程可以简化为:首先通过一个预设的 “加噪” 过程,将一张干净图像 $x_0$ 逐步变成纯噪声 $x_T$;然后训练一个神经网络,让它学会从任意时刻 $t$ 的含噪图像 $x_t$ 中,恢复出一些关键信息,从而实现 “去噪” 生成。
加噪过程通常表示为:
其中,$z_t$ 是 $t$ 时刻的含噪图像,$x$ 是原始干净图像,$\epsilon$ 是标准正态分布的噪声,$t$ 从 0 到 1 变化。
模型的任务就是从 $z_t$ 预测出 $x$、$\epsilon$ 或流速 $v$(定义为 $v = x - \epsilon$)。虽然这三者在数学上可以相互转换,但作者指出,让网络直接输出什么,至关重要。
论文作者展示了三种预测目标(prediction)和三种损失函数(loss)的所有组合方式,如下图所示:

JiT:大道至简的 Transformer
基于以上洞察,作者提出了 JiT (Just image Transformer) 架构。
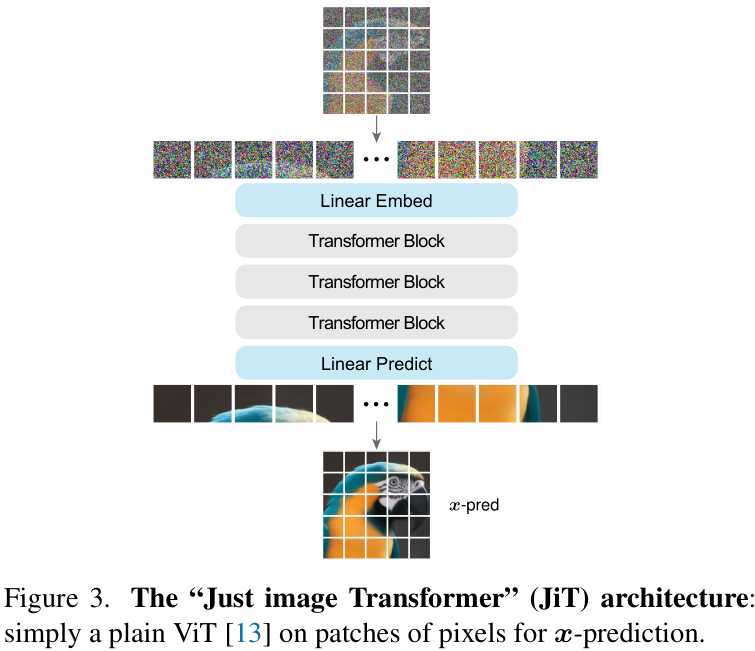
- 纯粹的 ViT:就是一个标准的 Vision Transformer,没有 U-Net 那样的下采样和上采样结构。
- 操作于像素块:直接将图像分割成大块的 patch(例如 16x16 或 32x32),然后送入 Transformer。
- 三无产品:无分词器 (tokenizer),无预训练,无额外损失函数(如感知损失)。
- 坚定地执行 x-prediction:网络的目标永远是直接输出预测的干净图像。
总结
这篇论文的核心贡献是清晰而深刻的:它重新审视了扩散模型的基础,并有力地论证了“直接预测干净图像”(x-prediction)相较于“预测噪声”($\epsilon$-prediction)的根本优势,尤其是在处理高维原始数据(如像素)时。
JiT 的成功表明,一个简单、自包含的“Diffusion + Transformer”范式,有潜力成为未来生成模型的基础。它不仅在性能上具有竞争力,更在概念上回归了“去噪”的本质,为我们揭示了一条更简洁、更高效的道路。