Self-Distillation
传统的强教师依赖范式因成本与数据依赖,难以适配高频的持续进化。Self-Distillation(自蒸馏) 随之成为破局点 —— 通过合理的上下文引导或反馈机制,模型完全可以构建出一个比当前权重更聪明的临时自我,让模型在没有外部强教师的情况下实现内生增长。
仅记录学习疑问以及关键信息
关键信息
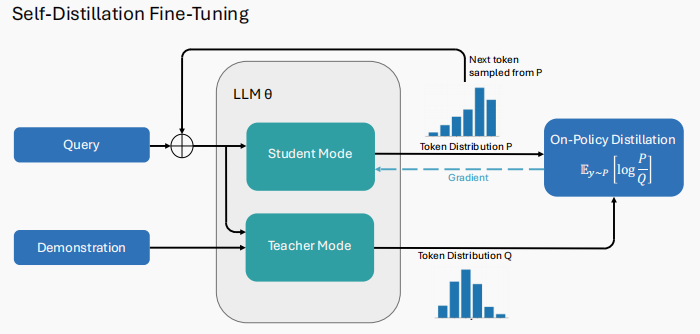
1. 自蒸馏微调(SDFT, Self-Distillation Fine-Tuning)
整个过程主要包含两个阶段,对应图中的两种模式:
- 第一阶段:教师模式
在这个阶段,模型会像做“阅读理解”一样,看到几个高质量的示范例子。这时模型进入“教师”状态,由于有示范的引导,它能产生一个质量非常高的答案概率分布 $P$,我们可以把这个分布理解为“标准答案的思考过程”。 - 第二阶段:学生模式
接下来,把示范例子拿掉,让同一个模型进入“学生”状态。模型在没有提示的情况下,自己尝试生成一个答案概率分布 $Q$,这相当于它“凭自己的理解”给出的答案。 - 核心步骤:对齐与蒸馏
训练的目标,就是让“学生”的思考过程(分布 $Q$)去模仿“老师”的思考过程(分布 $P$)。图中提到的“On-Policy Distillation”公式 $E_{y \sim p} [\log \frac{P}{Q}]$ 就是实现这一对齐的数学方法。
💡 Demonstration 是什么?
Demonstration 指的是在教师模式阶段提供给模型的少量专家演示,也就是我们常说的 Few-shot 示例。可以把它理解为给模型的“答题范例”或“标准答案示范”。
具体形式:假设你想让模型学习一个新的任务(比如一种新的逻辑推理方式)。Demonstration 通常会包含几个完整的例子。例如:
• 例子1:问题:2+2=? 答案:4
• 例子2:问题:3+5=? 答案:8
💡 Token Distribution P 是什么?
Token Distribution P 是模型在教师模式下,看到 Demonstration 之后所生成的答案概率分布。
- P 代表“教师分布”:由于模型是在有高质量示范引导的情况下生成的,此时它处于最聪明、最专注的状态。因此,它生成的这个概率分布 P 被认为是高质量的、理想的、接近正确答案的思考路径。图片中将其描述为“标准答案的思考过程”。
- 与 Q 的关系:在随后的“学生模式”中,模型在没有 Demonstration 的情况下会生成另一个分布 Q。SDFT 的核心目标,就是让分布 Q(学生的普通思考)去学习和模仿分布 P(老师的优质思考)。
小结: Demonstration 是喂给模型的输入,作用是让模型进入最佳状态。Token Distribution P 是模型在最佳状态下产生的输出概率,作用是作为学生模式学习的标杆。
2. SDPO(自蒸馏策略优化)
SDPO 的核心机制
图片下半部分描述了 SDPO 的工作流程:
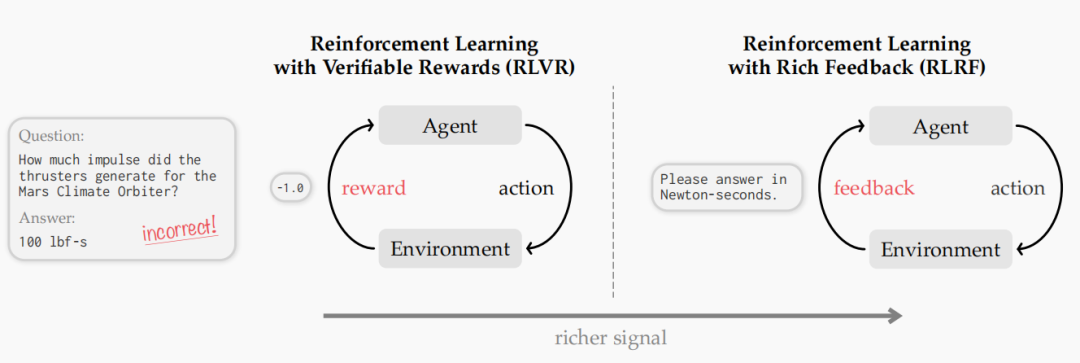
- 引入富反馈环境:当模型生成的答案是错误的时候,环境不会仅仅返回一个“0分”,而是会返回一个具体的报错信息(例如:“第三步逻辑错误:变量未定义”)。
- 构建“自省教师”:模型收到这个报错信息后,会把这些信息重新注入到上下文中。此时,模型结合错误提示,扮演一个“自省教师”的角色,重新审视之前的错误尝试。
- 自蒸馏与 Token 级监督:
- 模型在“看到反馈后”会生成一个新的、正确的思考分布。
- SDPO 通过对比“反馈后的正确分布”与“**初始的错误分布**”,能够精确地找出是哪个 Token(哪个词或步骤)导致了失败。
- 然后,它引导模型降低那些错误 Token 的概率,同时提高修正后逻辑的置信度。
3. OPSD(策略内自蒸馏)
OPSD 的训练流程
图中的流程图清晰地展示了 OPSD 的运作步骤:
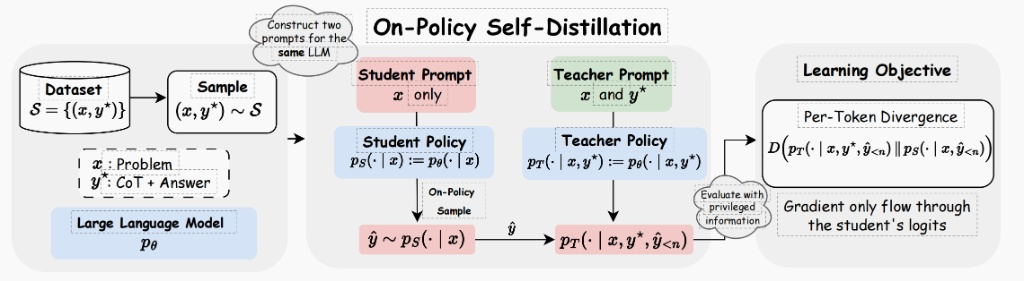
- 数据采样:从数据集中取出一个样本 $(x, y^*)$,包含题目和带答案的思维链。
- 构造双提示:基于同一个样本,构造两种提示:
- 一条只给模型看题目 $x$。
- 另一条给模型看题目 $x$ 和标准答案 $y^*$。
- 策略内采样:
- 学生根据题目 $x$ 生成一个回答 $\hat{y}$。
- 注意:这里特意标注了 On-Policy Sample。这意味着用来计算损失的回答 $\hat{y}$ 是学生自己实时生成的,而不是从数据集中取的静态答案。这是保证“策略内”属性的关键。
- 分布对齐:
- 教师根据 $(x, y^*)$ 生成理想的 Token 概率分布。
- 学生根据 $x$ 生成实际的 Token 概率分布。
- 训练目标是最小化这两个分布的差异,即 KL 散度。
学习疑问
1. ICL 是什么?
ICL 的全称是 In-Context Learning,中文通常翻译为“上下文学习”。
1.1 ICL 的工作原理
传统的机器学习需要通过“训练”来改变模型参数。而 ICL 的逻辑是:
- 输入:几个“输入-输出”对作为示例(Few-shot)。
- 过程:模型通过观察这些示例中的模式、格式和逻辑。
- 结果:在处理下一个类似问题时,模型能直接给出符合要求的答案,而模型本身的权重保持不变。
例子:如果你想让模型学会“中英翻译”,你给它如下提示词:
苹果 -> Apple | 香蕉 -> Banana | 西瓜 -> (此处模型会自动预测出 Watermelon)
在这个过程中,模型并没有因为这几个词进行了“重新训练”,而是通过上下文学习直接推断出了任务逻辑。
1.2 ICL 的核心特点
- 无需微调(Training-free):它发生在推理阶段(Inference time),不改变模型权重。
- 涌现能力(Emergent Ability):小参数量的模型通常 ICL 能力很弱,当模型达到一定规模时,这种能力会突然爆发。
- 敏感性:ICL 的效果高度依赖于示例的质量、顺序和格式。
2. 损失如何训练模型参数的?
反向传播与参数更新
这是训练发生的实际环节:
- 梯度计算:损失 $\mathcal{L}$ 是一个数值。计算机开始自动求导(反向传播)。梯度会沿着计算图往回走。由于我们设计的时候,只有学生路径的参数参与了损失的计算(教师路径的梯度被阻断,因为教师的目标分布被视为常数),所以梯度只会流经学生模式下的模型参数。
- 参数更新(以 LoRA 为例):假设我们用了 LoRA(低秩适应)进行高效微调。模型的原参数暂时冻结,只有 LoRA 的 A 和 B 矩阵参数在接收梯度。
$$ \theta_{\text{LoRA}}^{\text{new}} = \theta_{\text{LoRA}}^{\text{old}} - \eta \cdot \nabla_{\theta_{\text{LoRA}}} \mathcal{L} $$更新后的效果:经过这次更新,模型参数发生了微小的变化。下次当模型再见到类似的问题 $x$ 时,学生模式生成的分布 $p_S$ 会向这次教师模式产生的 $p_T$ 靠近一点点。
- 循环迭代:拿下一个 batch 的数据,重复上述过程。随着迭代次数增加,学生模式的参数被反复调整,逐渐学会了在没有标准答案的情况下,也能输出接近“见过答案时”的推理分布。