1. Introduction (引言)
现有研究方法,无论是基于 Transformer 还是大语言模型 (Large Language Models),往往存在一些局限性:它们要么只关注单一的数据维度(如时间或频率),导致信息表征不完整;要么采用固定的信息融合策略,无法根据不同的预测时长灵活调整模型;要么难以有效整合不同类型(如数值和文本)的信息。
痛点一:无法根据预测时长灵活调整
举例理解: 现有的某些模型太“死板”了。它们处理信息的方式是一成不变的,不管你是想预测“明天”的股价,还是预测“明年”的股价,它都用完全一样的方法去权重数据。
为什么这是个问题? 因为短期预测和长期预测关注的重点完全不同!
- 短期(比如预测明天): 可能更看重今天的交易量、刚出的突发新闻(比如“CEO今天感冒了”)。
- 长期(比如预测明年): 可能更看重公司的整体财报、行业趋势(比如“新能源是未来”)。
通俗比喻: 这就像你出门穿衣服。如果你的策略是“固定的”(比如只穿短袖),夏天(短期)没问题,但冬天(长期)就会冻死。一个好的模型应该能根据“季节”(预测时长)灵活调整穿什么。
痛点二:难以有效整合数值与文本信息
有些模型虽然灵活一点,但它们是个“偏科生”。它们很难把“数字”和“文字”这两类完全不一样的东西融合在一起思考。
- 数值 (Numerical): 比如昨天的收盘价是100元,成交量是500万手。这是冷冰冰的数字。
- 文本 (Textual): 比如新闻报道说“该公司发布了重磅新产品”或者网友评论“这公司要凉”。这是文字信息。
计算机处理数字很擅长,处理文字也很擅长,但要让它同时理解这两者并得出结论很难。很多模型要么只看K线图(忽略新闻),要么只分析舆情(忽略K线图),很难把“100元”和“好消息”这两个概念放在同一个锅里炒出一盘好菜。
本论文提出了 T3Time,一个三模态自适应对齐与融合的预测框架。该框架创新性地同时从时间、频率和文本三个维度提取数据特征,并通过自适应的对齐与融合机制,动态地整合这些信息。
2. 研究原理
论文提出的 T3Time 模型,其核心思路是 将时间序列从时间、频率和文本三个不同模态进行编码,再通过动态、自适应的融合机制生成一个全面而鲁棒的特征表示,最后用于预测。
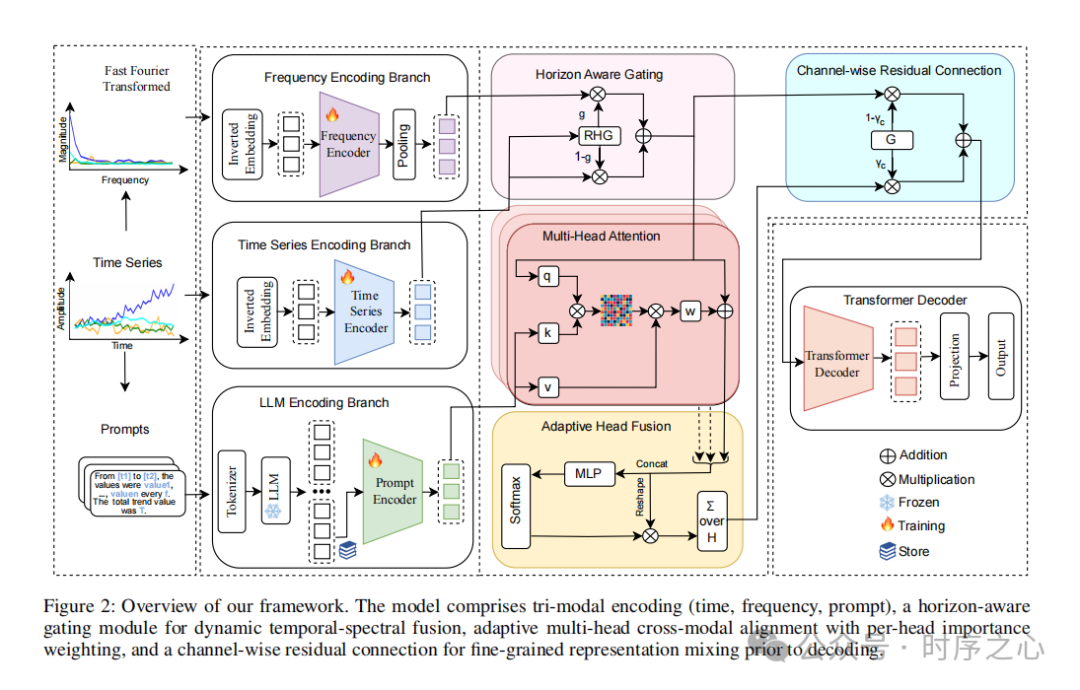
2.1 三模态编码 (Tri-Modal Encoding)
① 第一位专家:专门找规律的“频率分析师”
对应图中位置: 最上面的分支 (Frequency Encoding Branch)
他是干嘛的? 他根本不看具体的股价是100块还是101块,他只看“周期”。
怎么工作的?
- 输入: 利用傅里叶变换(FFT),把随时间波动的线,变成频率图(图左上角的尖峰图)。
- 通俗理解: 就像听音乐。原始数据是听到的歌声,而这位专家是看音响上的均衡器(低音重不重、高音亮不亮)。他能瞬间发现隐藏的规律,比如“这支股票每隔30天就会跌一次”或者“每年冬天销量都高”。
- 处理: 他把这些频率特征提炼出来,生成一个精简的“频率报告”($\tilde{F}$)。
② 第二位专家:实干派的“看图操盘手”
对应图中位置: 中间的分支 (Time Series Encoding Branch)
他是干嘛的? 他是传统的实干家,直接看原始数据的走势,关注“变化”。
怎么工作的?
- 输入: 最原始的时间序列数据(五颜六色的折线图)。
- 通俗理解: 他就是盯着K线图看的人。他负责捕捉“昨天涨了,今天跌了,明天可能会反弹”这种直接的时间演变关系。
- 处理: 他把一段时间的数据打包(Embedding),用 Transformer 去分析这些数字前后的依赖关系,生成“时序特征报告”($\tilde{Z}_t$)。
③ 第三位专家:博学多才的“语言翻译官”
对应图中位置: 最下面的分支 (LLM Encoding Branch)
他是干嘛的? 这是这个模型最创新的地方。他把冷冰冰的数字翻译成“人话”,然后请教在大数据里泡大的 GPT-2(大语言模型)。
怎么工作的?
- 翻译过程: 模型会自动把数据写成句子。比如把“10:00 股价10元...”翻译成提示词 (Prompt):“从10点到10点15,数值呈现上升趋势,整体涨幅明显...”。
- LLM的作用: 图中的雪花图标代表“冻结 (Frozen)”。意思是我们不重新训练 GPT-2,直接借用它已经学到的海量知识。就像你遇到难题,把题目读给一位博学的教授(GPT-2)听,教授虽然不专门炒股,但他读过万卷书,能根据你的描述给出很深层的语义理解。
- 处理: 最终提取出这段文字背后的深层含义($Z_{LLM}$)。
注:“时间和频率”并不是两份独立收集的数据,而是同一份原始数据,经过‘变身’后得到的两种不同形态。
2.2 预测期感知门控模块 (Horizon-Aware Gating Module)
解决了一个核心痛点:预测“下个月”和预测“下一秒”,需要看的东西是完全不一样的。
怎么做的?(How)
核心动作:制作一个“智能滑块”。这个模块内部有一个小型的神经网络(MLP),它接收两个关键信息:
- 你想预测多久 (Horizon):未来 1 小时(短)还是 30 天(长)?
- 当前数据的概况。
它会算出一个数值 $g$,这是一个 0 到 1 之间的小数。你可以把它想象成混音台上的推子。
有什么用?(Why)
防止“死板”。短期预测(如股价波动)时序特征更重要;长期预测(如空调销量)频率/周期特征更重要。这个模块负责识别任务性质。
怎么发挥作用?(Mechanism)
公式如下:
假设 $\tilde{F}$ 是频率专家,$\tilde{Z}_t$ 是时序专家:
- 长期任务: $g=0.9$。结果中 90% 是频率专家的意见。
- 短期任务: $g=0.1$。结果中 90% 是时序专家的意见。
2.3 自适应动态多头交叉模态对齐
任务是:把冷冰冰的数据 ($Z_g$) 和热乎乎的文本知识 ($Z_{LLM}$) 真正融合在一起。
过程分为三步:
- 角色分配与提问 (Cross-Attention): “数据”($Z_g$) 作为 Query 去查阅“知识库”($Z_{LLM}$) 作为 Key/Value。
- 多头并行分析 (Multi-Head): 多个“头”同时从不同角度寻找联系。
- 自适应头融合 (Adaptive Head Fusion): 关键创新点。引入门控网络给每个“头”打分。
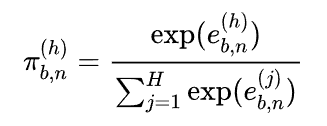
公式详解
1. 左边 $\pi_{b,n}^{(h)}$ —— 最终话语权:
这是第 $h$ 个头最终获得的“股份占比”。注意角标 $n$ 代表变量,这意味着模型为每一个变量(如“股价” vs “交易量”)单独计算权重。
2. 分子 $\exp(e_{b,n}^{(h)})$ —— 放大得分:
$e$ 是原始打分,$\exp$ 函数将其变为正数并拉大差距(让强者更强)。
3. 分母 $\sum \exp(\dots)$ —— 全场总分:
归一化操作,确保所有头的权重加起来等于 1。
最终对齐表示:根据分数,对所有“头”的输出进行加权求和。
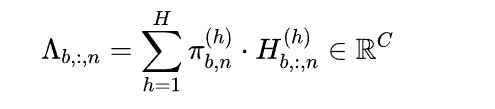
2.4 通道级残差连接与解码器
这是整个模型的“最后一道把关程序”。
输入两份资料:
- $Z_g$ (原始时频特征):客观数据的“基本盘”。
- $\Lambda$ (交叉对齐特征):融合了 LLM 知识的“增量信息”。
通过可学习参数 $\gamma_c$ 进行融合:
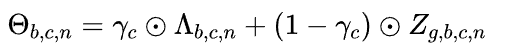
3. 总结
T3Time 模型在理论上提出了一个整合时间、频率和语义信息的三模态框架。通过引入预测期感知的门控、自适应多头交叉模态对齐和通道级残差连接等机制,实现了对多源信息的动态、高效融合。实验证明,该模型在标准长期预测及小样本学习场景下均展现了卓越性能。
4. 待改善与局限性
- 计算成本较高: 集成三个编码器分支(含LLM)和复杂注意力模块,对硬件资源要求较高。
- 提示工程依赖: 模型性能依赖于将时间序列转化为自然语言提示的质量。如何设计最优 Prompt 仍需探索。
- 对齐机制局限: 目前的“软”对齐可能存在对齐不足或过度对齐的风险,未来可探索更显式的对齐约束。