计算机应用研究 | 2024年综述 —— 针对大语言模型的偏见性研究:从划分、评估到缓解方法,以及大型语言模型中的去偏策略。
思考
1. 对抗学习与自适应模型解决偏见是怎么做的?
偏见划分及来源
内在偏见是预训练模型在训练时得到的固有偏见,而外在偏见则是模型在针对下游任务微调时学习到的偏见。
偏见来源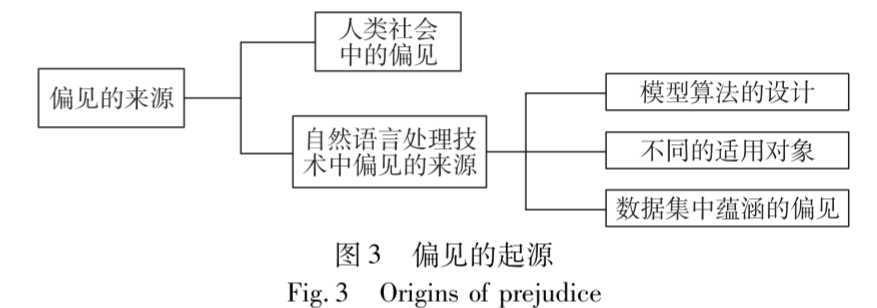
自然语言技术中的偏见主要来自:
1. NLP技术的研究设计方面(模型算法的设计): 不论是n-gram模型还是词嵌入技术,大多都立足于英语语料进行训练,使得NLP技术产生了对英语的偏倚。
最初的研究设计中,NLP研究人员将语言视为多个单词出现和同时发生的概率,而忽视了语言在不同背景下所反映出的社会关系。而简单依赖于单词的共现,将“女人”和“男人”与“护士”和“医生”联系起来,最终造成了偏见。
2. 适用对象方面:当一个模型在由一组人生成的文本数据上进行训练,随后被部署到现实世界并被更多不同的群体使用时,偏差就会显现出来。(文化环境差异)
3. 有监督的数据集:数据和标注标签出现偏差背后有很多原因,可能是由于数据标注者对任务缺乏先见知识从而导致的偏差,也可能是因为标注者本身就对某些群体存在歧视从而导致标注的数据存在偏见,而直接采集的无监督的数据集所展现的就是原生的人类自然语言,所以包含了社会中的各种偏见。
偏见评估方法
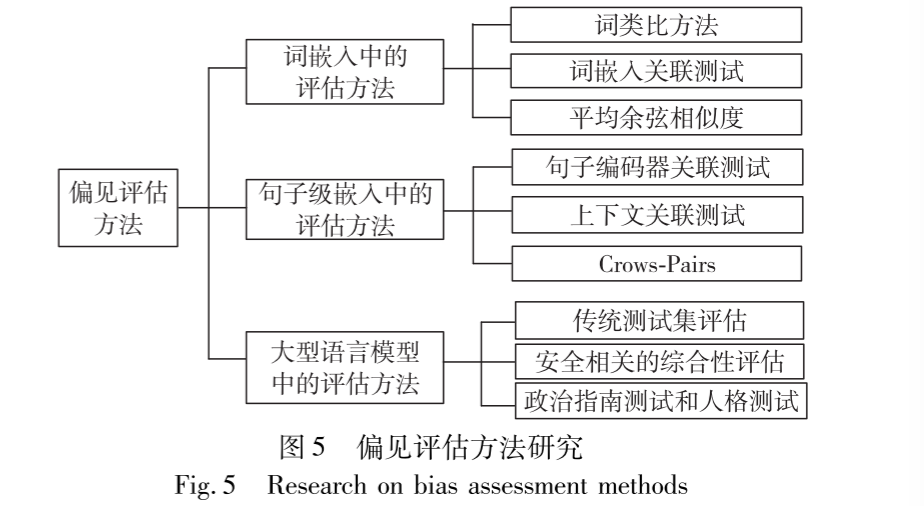
WEAT
WEAT 想回答一个问题:两组概念(如艺术类职业 vs. 科学类职业)与两组属性(如女性 vs. 男性)在语义空间中的关联程度。
衡量的是w与各属性平均余弦相似度之间的差,即w的偏好得分【单个词的偏好得分】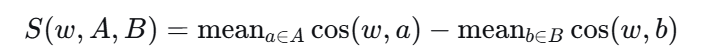
S(x,y,A,B)是衡量两组目标概念与属性的差异关联,即两组概念的比较偏好得分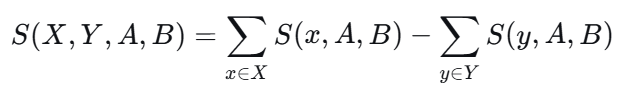
显著性检验(置换检验)
- 将 (X) 和 (Y) 中所有词合并,然后随机打乱,重新分成两组大小相等的新集合 (X_i) 和 (Y_i)(这叫“置换”)。
- 计算新分组的 (S(X_i, Y_i, A, B))。
- 重复很多次(比如10000次),统计这些随机分组中,得分大于原始分组得分的次数比例。
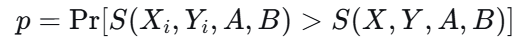
效应量(偏倚程度)
p值只能告诉你“有没有”,d值告诉你“有多大”。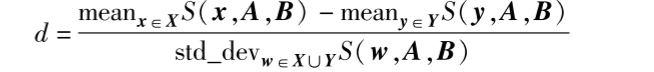
对比方法

传统偏见缓解方法
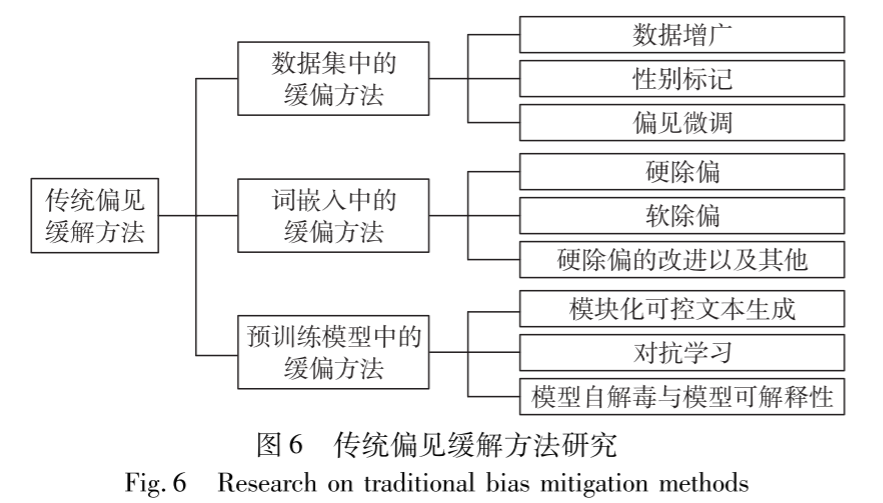
数据集中的操作
数据增广
Zhao等人提出将数据集中句子的性别替换的方法,例如“Marry喜欢她的母亲”变成“Marry喜欢他的母亲”。
性别标记
性别标记通过对数据开头添加标记来指明数据源的性别,从而避免对于没有指明来源的输入模型倾向于来源于男性的偏见。例如,“我很高兴”会变成“[男]我很高兴”。
偏见微调
- 第一步(迁移学习): 先在一个相关但无偏见的数据集上进行训练。这一步是为了给模型打下一个“正义”的底子,确保模型包含最小的偏见。
- 第二步(微调): 在这个“底子”基础上,再去使用那个虽然有偏见但针对目标任务的数据集进行微调。
- 效果: 这样做可以让模型学到执行任务所需的技能,但因为有了第一步的“免疫打底”,它就不容易被第二步数据中的偏见带偏。
词嵌入中的缓偏方法
硬除偏算法
1. 核心思路:把“偏见”看作一个方向
在计算机眼里,每个词都是高维空间里的一个点(向量)。科学家们发现,在这些词向量空间里,“性别”往往表现为一个特定的方向。
- 比如,“男人”到“女人”的方向,和“国王”到“女王”的方向几乎是平行的。
- 问题在于:一些中性词(如“医生”、“护士”、“哲学家”)在向量空间里,也会莫名其妙地偏向“男人”或“女人”的方向。这就是偏见。
2. 算法的三个主要步骤
第一步:找到“性别子空间” (Identifying the Bias Subspace)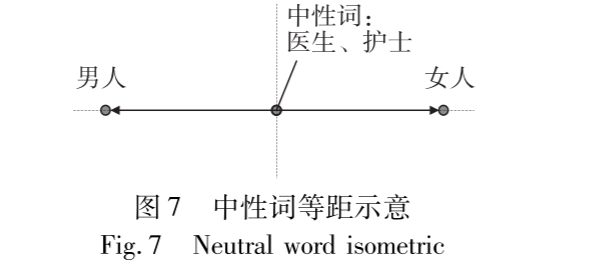
算法先找出一组定义性别的词对,比如 {男人, 女人}、{他, 她}。通过计算这些词对之间的差异,确定出空间里哪一个方向是代表“性别”的。
- 文中的公式 (14): $w_B$ 代表词语 $w$ 在性别方向上的“分量”。你可以把它理解为这个词里含有多少性别的影子。
第二步:中性化 (Neutralize) —— 抹除影子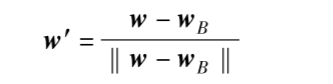
对于那些本该中性的词(如:医生、程序员、家务),我们要把它们身上“性别的影子”删掉。
- 文中的公式 (15): 用原始词向量 $w$ 减去它的性别分量 $w_B$。
- 直观理解: 就像在地图上,如果“北”代表性别。一个中性词如果往北偏了,我们就把它强行拉回到赤道线上,让它在性别维度上的值为0。
第三步:均等化 (Equalize) —— 保持对称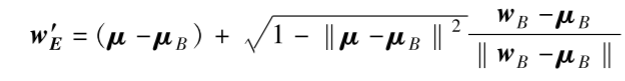
对于那些本身就有性别意义的词对(如:男人/女人),我们不能抹除它们的性别(否则就分不清男女了),但要确保它们相对于中性词是绝对对称的。
- 如图7所示: 经过处理后,“医生”这个中性词到“男人”和“女人”的距离是完全相等的。
- 文中的公式 (16): 这是一个数学修正,确保像 {男人, 女人} 这样的词对,除了性别差异外,在其他属性上是完全平等的。
软除偏算法
软除偏认为:我们不需要强行把偏见降为0,而是要通过一个线性变换(矩阵 $A$),让模型在“保留原始含义”和“减少性别关联”之间达到一种平衡。
其他方法
- 带有性别关联的普通名字(例如John、Amy)通常会比使用带有性别的词(例如he、she)提供更有效的性别子空间。同时因为人类姓名中往往包含种族、国籍、地域等特征,这些特征会导致一些固有的偏见,而通过这些通用的名称来确定偏见方向并从词嵌入中去除偏见是有效的。
- 现单词频率的变化也会影响词嵌入子空间的性别方向,因此提出了双重硬除偏(doublehard debiaing)来消除单词频率的负面影响。
- 双重硬除偏 (Double-Hard Debiasing):
- 第一重: 先识别并去除由于“词频”导致的影响。
- 第二重: 在干净的基础上,再进行传统的性别除偏。
- 结果: 这种“双重手术”能更彻底地把偏见剥离出来,而不受词语出现频率高低的影响。
- 双重硬除偏 (Double-Hard Debiasing):
预训练模型中的缓偏方法
模块化可控文本生成方法
先前的可控文本生成方法不论是使用强化学习微调,还是训练生成对抗网络或者训练条件生成模型,都是在训练阶段进行,且模型针对每个特定的属性都需要分别进行微调,这往往是代价高昂的。
第一种方法:PPLM (即插即用的语言模型)
这是由 Uber 研究人员提出的一种经典方法。
- 做法: 像插 U 盘一样,在现成的大模型上面“插”一个小的分类器(属性模型)。
- 优点:
- 省钱省力: 不需要重新训练那个巨大的底座模型。
- 灵活: 想控制什么,就换什么样的分类器。
- 缺点:
- 慢: 生成每个词的时候,它都要根据分类器的反馈去反复调整大模型的内部参数(梯度下降),导致推理速度很慢。
第二种方法:FUDGE (未来判别器)
这是对 PPLM 的一种改进方案,更加“模块化”。
- 改进点:
- 不看内部: PPLM 要进到大模型肚子里去改参数,而 FUDGE 只看大模型的输出结果(概率分布)。
- 预测未来: 它的判别器很聪明。哪怕句子才写了一半(前缀),它就能预测:“按照目前这个趋势写下去,最后整句话能满足要求 $a$ 吗?”
- 例子: 如果要求生成“积极情感”的句子。当模型刚写出“今天我...”,FUDGE 就会看接下来接“摔跤了”还是“中奖了”哪个更能让最终结果变积极,从而引导模型选“中奖了”。
对抗学习
(原文此处未展开,保留标题作为结构完整性)
模型自解毒与模型可解释性
Schick 等人发现了一个有趣的现象:大模型其实知道自己说的话好不好。
1. 模型自解毒(Self-Debias/Self-Diagnosis)
Schick 等人发现了一个有趣的现象:大模型其实知道自己说的话好不好。
- 自我诊断(Self-Diagnosis): 当模型生成了一句话(比如:“我要逮捕你!”)之后,我们可以反过来问模型:“你刚才说的那句话包含‘威胁’属性吗?”
- 数学公式 (18) 的直白含义: 这个公式是在计算模型认为自己生成内容“有毒”的概率。它通过比较模型输出“Yes”和“No”的概率大小,来给这句话的有害性打分。
- 如何去偏: 一旦模型“意识到”某个词可能会导致偏见或有害性,算法就会调低那个词出现的概率,从而强迫模型换一种更友好的表达方式。
总结: 模型的诊断能力受限于它的训练数据。为了降低风险,自解毒算法可能会倾向于压制所有带有强烈情感或争议性的词汇,模型输出变得极其乏味、平庸、公式化。在文学创作、激烈辩论或新闻报道等需要真实表达情感的场景下,这种“自解毒”可能会误伤正常的表达,导致模型不敢说真话或不敢用生动的词汇。无法处理那些需要实时更新的社会道德准则。
2. 模型可解释性:FFN层是“知识仓库”
Geva 等人通过研究 Transformer 模型的内部结构(特别是 FFN 前馈神经网络层),揭示了模型是如何存储概念的。
- 发现: FFN 层就像是一个巨大的“键值对”仓库。每一层参数的更新,其实都对应着某个具体的“概念”。
- 例子: 当模型想到“早餐”这个概念时,FFN 层里的某些神经元就会“通电”,从而带起“馅饼”、“牛奶”这些相关词的概率;同时,和早餐无关的词(比如“坦克”、“宇宙”)概率就会下降。
- 应用策略(内部手术): 既然我们知道了哪些神经元对应哪些概念,研究者就提出:
- 手动寻找那些代表“积极”、“友好”、“中性”的概念。
- 在模型生成时,人为地给这些正向概念的神经元“加把劲”(促进子更新)。
- 从而从底层原理上,降低模型输出偏见和有害内容的可能性。
潜在问题
例子 A:历史事实的“美化”与“遗忘”
事实知识:“希特勒(Hitler)发动了第二次世界大战,并实施了种族大屠杀。”
干预手段:为了让模型更“友好、积极”,算法决定抑制所有与“仇恨”、“屠杀”、“邪恶”相关的 FFN 子更新,转而促进“和平”、“友爱”的概念。
后果:当用户询问二战历史时,模型为了符合“友好”的设定,可能会变得言辞闪烁,甚至出现历史修正主义。它可能会回答:“那是一段复杂的历史,我们要关注人类对和平的渴望。”从而淡化或抹去了真实的历史罪行,导致事实错误。
例子 B:医学/科学中的“报喜不报忧”
事实知识:“吸烟(Smoking)会导致肺癌,增加死亡风险。”
干预手段:算法识别到“癌症”、“死亡”、“风险”属于负面、令人不安的概念,为了降低输出的有害感,抑制了这些概念的权重。
后果:当用户询问吸烟的危害时,模型可能会因为相关负面概念被抑制,而无法准确、严肃地陈述其致病性,甚至可能给出“吸烟是一种个人生活选择,保持心情愉悦最重要”这种误导性甚至致命的建议。
例子 C:统计事实与社会公平的冲突
事实知识:“在某年某国,90%的育儿嫂(Nanny)是女性。”(这是一个客观统计事实,尽管它反映了社会分工的刻板印象)。
干预手段:为了消除性别偏见,算法强行将“育儿嫂”这个职业概念在 FFN 层与性别概念“脱钩”,并强行促进“性别中立”的概念。
后果:当一个社会学者询问模型该国当年的就业分布数据时,模型为了维持“无偏见”的设定,可能会谎称“该国育儿嫂中男女比例各占一半”。这时候,它为了政治上的“公平”,牺牲了科学上的“真实”。
大型语言模型中的缓偏方法
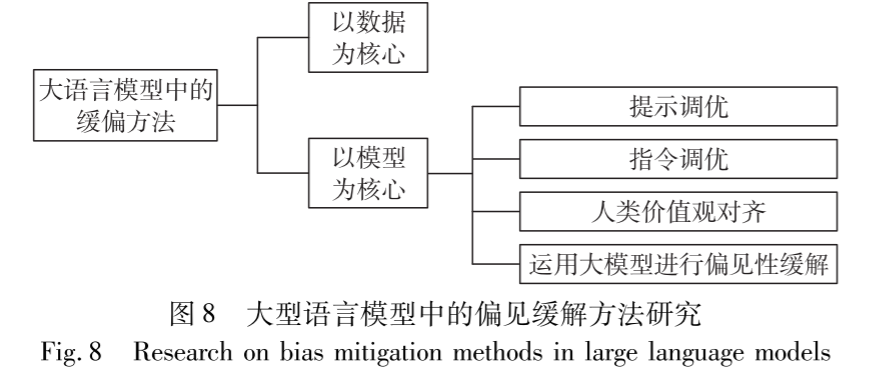
以数据为核心
方法一:直接“清洗”和“重建”数据集
研究者们尝试通过物理手段让数据变得更“干净”:
- 方言保护(Zhou 等人): 避免因为文化差异,把黑人等少数族裔常用的方言表达误标为“有害内容”。
- 脱敏处理: 识别并删除数据中的身份代词(如:他/她,黑人/白人),让模型在训练时“看不见”这些容易引起偏见的标签。
- 中文平衡数据集: 专门构建男女比例均衡的中文句子库,从源头打破性别刻板印象。
方法二:操纵数据的“权重”(更聪明的做法)
有时候,高质量的数据非常贵,直接删掉可惜。于是研究者提出了“权重管理”的思想:
- Han 等人的做法: 既然不能删,那就在训练时告诉模型:“这几条数据带有偏见,你别太当真。” 通过降低这些有偏见样本的“注意力权重”,让模型少学它们。
- Zhang 等人的理论(选择偏差): 他们把社会偏见看作一种“选择偏差”。
- 理想状态: 现实世界是公平非歧视的分布。
- 现实数据: 采集到的数据是经过“偏见滤镜”筛选后的歧视性分布。
- 解决方案: 通过数学手段,从这些带偏的数据中,反向推导出(恢复)那个不带歧视的分布。
以模型为核心
提示调优
A. 前缀调优(Prefix Tuning - Li 等人)
- 做法: 把大模型的参数全部“冻结”(不动它)。在模型的每一层(Layer)前面偷偷加上一小段可以训练的“前缀”向量。
- 比喻: 就像给一个经验丰富的老师配了一个“随身翻译”,老师的知识(模型参数)不变,翻译通过在前头打招呼,引导老师处理特定的任务。
B. 提示调优(Prompt Tuning - 更进一步的简化)
- 做法: 连每一层的前缀都不要了,只在最开始输入层加一串可训练的向量(提示词向量)。
- 优点: 极其轻量化。对于一个千亿参数的大模型,你可能只需要训练和保存几千个参数,就能让它学会一个新任务。
指令调优
现在我们给它成千上万个格式化的例子(指令+答案),比如:“请把这段话翻译成英文:xxx”。
去偏见手段:比如文中的 GEEP 和 ADEPT 技术,就是通过在指令里加入特定的“引导语”,让模型在生成时自动避开性别歧视或刻板印象。在输入指令时,偷偷加上一些“隐形规则”(连续提示词或指令令牌),告诉模型:“在生成回答时,请务必保持中立。”
潜在问题:
如果你随机给这些向量赋初始值,模型可能很难收敛。提示词长度也很难选:加 10 个向量可能不够,加 100 个又可能导致过拟合。
在多任务并发时,如果你为 100 个用户同时服务,而这 100 个用户用的是 100 种不同的提示调优插件,服务器需要频繁切换这些向量,管理起来非常复杂。
如果你同时叠加了一个“去偏见插件”和一个“翻译插件”。由于它们都是在冻结的模型底座上强行引导,它们之间可能会产生意想不到的干扰,导致翻译出来的文字虽然没偏见,但语义完全错了(也就是之前提到的影响事实知识)。
人类价值观对齐
训练数据里有很多垃圾信息和偏见,模型学了之后可能会说出伤人、造谣或危险的话。我们需要让它符合 3H标准(Helpful-有用, Honest-诚实, Harmless-无害)。


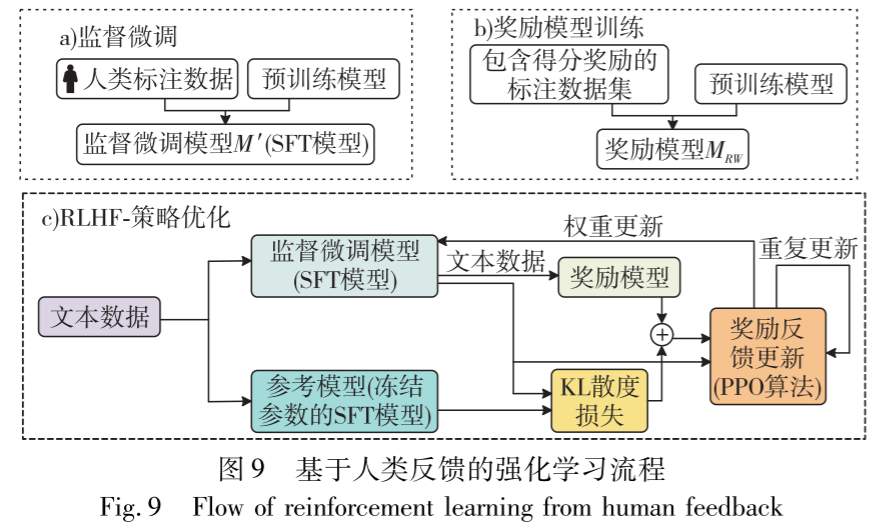
值得关注的
不同偏见的通用处理方法
偏见包含性别、种族、职业、宗教等方面,但目前的大部分偏见研究主要是针对性别偏见。先前已有研究表明,模型对于不同偏见的识别程度也不同,其中性别偏见的识别相对容易而宗教偏见的识别相对困难。因此探索通用的识别偏见和缓解偏见的相关方法是具有意义的。
语言模型作为处理偏见的工具
实际上,彻底消除模型中的偏见极具挑战,因为这些偏见源于人类社会,而在现实生活中,完全避免偏见是不可能的。然而,在提高模型公平性的同时,可以充分利用大型语言模型卓越的文本处理能力,将其应用于偏见评估和缓解领域,这一研究方向颇具探索价值。
多模态模型中偏见的相关研究
随着GPU等计算资源的快速发展,多模态研究得到了广泛关注。GPT4和ChatGPT相较于之前的模型,已经扩展了对图像处理的支持。考虑到文字生成图像任务在当下的流行程度,对多模态模型的偏见性问题进行研究具有重要意义。此外,由于图像相较于文字更能直观地传达内容,人们更容易从中感受到歧视。
中文公平性语料的缺乏
现有研究大部分都只关注英语,而中文的相关数据集很少。