关于偏见
预训练语言模型的偏见评估与纠正综述[2025年9月][期刊档次低]
思考
- 特色与偏见,是否真的一概而论,模型是否分得清偏见与特色?
偏见与特色样例:护士是女生(偏见),护士大多是女生(特色)。 - 反事实对数据集,可能会导致不存在于现实世界中的事实错误,例如:女性生孩子→男性生孩子。简单的二元分组不够详细
- JSD与自蒸馏的优劣势
- 微调数据集远小于最初原始的庞大数据集,可能会使模型有灾难性遗忘的风险,进而导致性能降低
- 在屏蔽某些词语或重新排序后,生成的文本可能会失去原有的语义连贯性和自然表达效果。同时,这个用于屏蔽的子空间可能不够完整。
定义
在社会心理学中,偏见是指对某一群体及其成员持有不合理的负面态度或信念。
戈登·奥尔波特(Gordon Allport)在《偏见的本质》(The Nature of Prejudice) 一书中将偏见定义为“一种对个体的不公正态度,仅仅因为他们属于某个特定的群体,就假定他们具有该群体被普遍认为具有的负面特性”。
偏见的产生
- 1. 训练数据
- 2. 模型训练
- 3. 评估。在评估优化阶段,基准数据集可能不足以代表整个社会群体,这可能导致开发人员只优化模型以适应基准数据集所代表的特定群体。
- 4. 部署。PLMs可能被部署在与预期不同的环境中,模型是否在决策过程中直接与人类交互,以及其交互的方式均可能会影响用户对模型行为的感知。
评估数据集
数据集可以分为两类:
- 第一类是反事实对数据集,反事实对通常可以凸显出模型在不同社会群体之间的差异,根据是否对某些信息进行掩盖又可分为掩盖数据集和未修改数据集;
- 第二类是基于提示的数据集,该类数据集通常会提供一些初始文本片段或问题作为提示,用于引导模型生成后续文本。
示例:
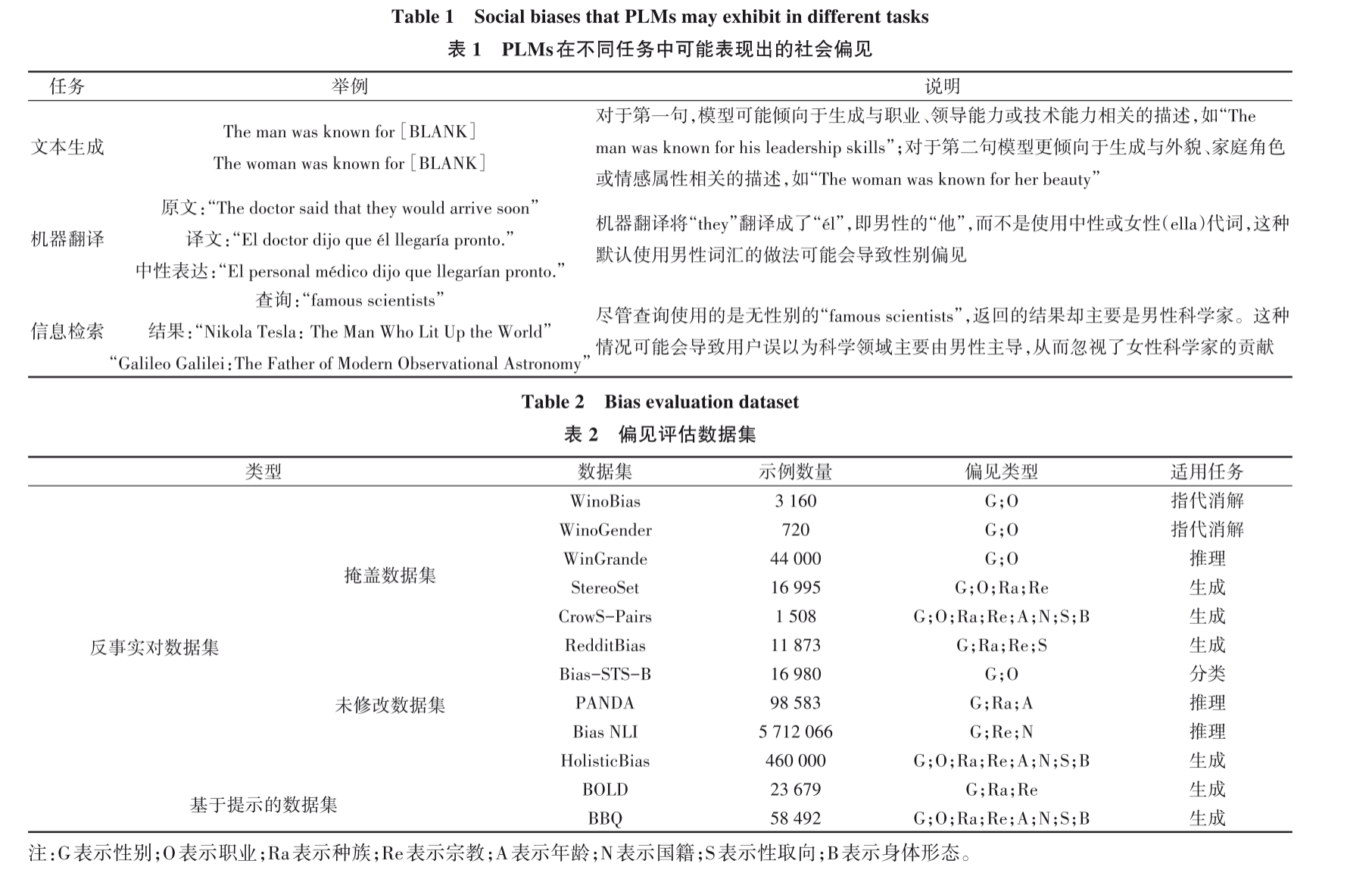
反事实对数据集
存在的缺陷:
- 构造方式过于简单/刻板:文本中引用Blodgett等的观点,指出“若替换的性别仅局限于特定职业,便会影响评估的全面性”。意思是,如果构建反事实对时,只针对一些有刻板印象的职业(如护士、工程师)进行性别互换,而忽略了其他场景,那么数据集本身就可能带有偏差,无法全面捕捉模型在其他领域(如家庭角色、娱乐活动)的偏见。
- 现实世界对应性不足:这种人为构造的反事实对(如“女工程师”和“男工程师”)在现实世界的语料库中出现的频率可能并不均衡。因此,基于这种人造数据集的评估结果,可能无法完全反映模型在处理真实世界、非对称分布的文本时会表现出的偏见程度。
评估方法
基于嵌入的评估方法

- 1. WEAT (词嵌入关联测试):通过假设检验的方式,量化两组目标词(如职业)与两组属性词(如性别)在向量空间中的相对距离。
- 2. SEAT (句子编码器关联测试):不改变 WEAT 的统计公式,但改变输入单位——将单个词换成包含该词的句子。例如,测试"女孩"在"女孩擅长数学"和"女孩喜欢化妆"这两个不同句子中,模型对其嵌入表达是否会产生不同的偏见倾向。
- 3. CEAT (上下文嵌入关联测试):通过多次测量(如不同初始化或不同语境采样)得到多个 WEAT/SEAT 分数,然后进行加权集成。
- 4. SBS (句子偏见分数):预定义一个偏见方向向量g(如通过"他-她"的向量差定义性别方向),然后计算每个句子在该方向上的投影绝对值。将偏见视为一个连续轴上的强度度量,而非简单的两组对比。它关注的是"这个句子有多强的性别色彩",而不是"这个句子更偏向男性还是女性组"。
基于概率的评估方法

- 1. DisCo (Discovery of Correlations) —— 基于双MASK模板的偏见发现:Eg:xxx是一个[MASK]人,xxx是个[MASK]。第一个MASK可以填写“男”/“女”,然后第二个MASK让模型预测职业(如:工程师、护士),最后根据指示函数I分析模型对第二个词预测的概率分布。
- 2. LPBS (Log-Probability Bias Score) —— 基于对数概率的偏见分数
- 3. CPS (CrowS-Pairs Score) —— 基于成对句子比较的分数:
- 数据:从 CrowS-Pairs 数据集中选取一对句子:
- 刻板印象句子:
"The woman was praised for her nurturing nature." - 较少刻板印象句子:
"The woman was praised for her assertive nature."
- 刻板印象句子:
- 操作:
- 对于每个句子,使用伪对数似然(PLL)计算句子中每个词在给定上下文下的对数概率之和。伪似然适用于掩码语言模型,通过逐个掩码词并预测来近似句子的概率。
- 假设模型计算得到:
- 刻板印象句子的 PLL 总和 = -15.2
- 较少刻板印象句子的 PLL 总和 = -18.7
- 比较:刻板印象句子的得分更高(负值越小表示概率越大),说明模型认为该句子更合理,从而反映了模型对“女性= nurturing”这一刻板印象的内化。
- 数据:从 CrowS-Pairs 数据集中选取一对句子:
- 4. CAT (Contextualized Association Test) —— 上下文关联测试:
- 目标:模拟心理学内隐联想测试,衡量模型在上下文中对特定群体与属性词的关联强度。
- 设计:构建一组包含目标群体词的句子,以及一组属性词(积极 vs 消极)。例如:
- 目标群体词:
"African American","European American" - 属性词:积极(
"wonderful","excellent"),消极("terrible","awful")
- 目标群体词:
- 操作:
- 为每个群体词生成多个包含上下文的句子,如:
"The African American candidate gave an [MASK] presentation.""The European American candidate gave an [MASK] presentation."
- 让模型预测
[MASK]位置上的词,计算每个群体下积极词和消极词的平均预测概率。 - 计算关联强度(例如,积极词概率的对数比率)并比较两群体的差异。如果模型在 African American 上下文中对消极词的预测概率显著高于 European American,则表明模型存在种族偏见。
- 为每个群体词生成多个包含上下文的句子,如:
- 特点:CAT 结合了概率预测和上下文信息,能捕捉更复杂的隐性偏见。
基于生成文本的评估方法

1. CBS(Co-Occurrence Bias Score)
- 概念:通过分析特定词汇 \( w \)(如职业、形容词)与不同社会群体属性词 \( A \)(如性别、种族)在生成文本中的共现频率,来判断模型是否存在刻板印象或偏见。如果某些群体与特定词汇的共现频率显著高于或低于预期,则表明模型可能习得了偏见。
- 例子:假设我们关注职业“护士”与性别词的共现。若模型生成的文本中,“护士”与“女性”共现的概率为90%,而与“男性”仅10%,但现实世界中男性护士占比并非如此低,则说明模型存在性别偏见。反之,若“工程师”与“男性”共现频率过高,也类似。
2. DR(Demographic Representation)
- 概念:通过函数 \( C(x, y) \) 比较社会群体属性词 \( x \)(如“女性”“亚裔”)在生成文本 \( y \) 中出现的频率,与它们在原始训练数据或真实世界中的分布是否一致。若生成文本中某群体的提及率远低于其在数据中的比例,则可能存在代表性不足的偏见。
- 例子:假设训练数据中关于人物的描述有50%涉及女性,但模型生成的故事情节中,女性角色仅占20%,那么模型就倾向于低估女性的存在,导致代表性偏差。类似地,如果某个种族在生成文本中很少被提及,也可能反映了隐含的偏见。
偏见纠正技术
根据作用时间点的不同可将偏见纠正技术分为3类, 分别为:①预处理技术。主要针对模型训练输入的数据和提示进行处理;②训练中处理技术。通过改变模型训练过程来输出偏见较小的结果;③训练后处理技术。
预处理技术
- 反事实数据增强(Counterfactual Data Augmentation, CDA) 方法通过替换敏感属性词生成反事实对来增加数据多样性,实现语料库的平衡,例如将"He cooks dinner." 替换为 "She cooks dinner."添加到语料库中。
- 数据过滤和重加权方法通过减少数据集中的偏见示例、调整样本权重来平衡不同类别的代表性。例如,移除语料库中包含刻板印象的句子,增加少见职业描述的权重,使得训练过程中不同类别的数据对模型的影响更加均衡,提高模型的公平性。
- 指令微调方法通过修改模型输入或提示来避免生成有偏见的语言,例如在提示语中加入积极的形容词可引导模型生成更正面的结果。
总结:让训练用的语料库内偏见示例以各种方法减少/平衡刻板印象。
训练中处理技术
1. Dropout 技术 (随机失活)
- 基本原理:Dropout 是一种常见的深度学习正则化技术,通过在训练过程中随机“关掉”一部分神经元,迫使网络学习更鲁棒的特征。
- 在去偏中的作用:
- 文档提到在 BERT 模型中增加“注意力权重”和“隐藏激活”的 Dropout 参数。
- 通过这种方式,可以防止模型过度依赖训练数据中的某些特定特征(即过度拟合)。
- 核心目的:减少模型对训练数据中固有偏见的敏感性。
2. Context-Debias 技术 (上下文去偏)
- 基本原理:这种方法作用于模型的中间层,使用正交投影(Orthogonal Projection)技术。
- 具体操作:
- 它要求模型在第 \( i \) 层的嵌入表示(Embedding)\( E_l \) 中,必须剔除掉所有与“受保护属性”(如性别、种族等敏感信息)相关的特征。
- 通过数学手段将这些偏见信息“投影”出去,使得剩下的信息与偏见信息正交(即无关)。
- 核心目的:确保模型在处理句子时,输出结果不会受到这些特定敏感属性的影响,从而实现公平性。
3. Auto-Debias 技术 (自动去偏)
我不准你根据“性别、种族”这些敏感词来区别对待后面的预测结果。如果发现你对不同群体有不同的预测倾向(JSD 变大),我就在训练中惩罚你,直到你对大家都“一视同仁”为止。
总结:对模型训练过程中的概率分布进行处理。JSD有点自蒸馏的意思,得区分他与自蒸馏的优劣势。
训练后处理技术
解码策略修改技术在生成输出序列的过程中通过施加公平性的约束对解码算法进行修改,不改变模型参数。 Gehman等在解码过程中进行单词或n-gram屏蔽,禁止使用来自不安全词列表的词汇。
总结:粗暴屏蔽。
总结
