解决一些关于bias的思考
思考
- 1.先学简单的,再学难的,逐一递进。
- 2.给偏见信息补充更全面(将社会性背景引入,使得模型理解这个问题出现不是特征,是因为特定社会情况导致的)——同时能学到新的知识背景并解决偏见。
- 3.叙事角度(学会事实知识而尽可能避免偏见?)
- 4.直接去掉受保护特征,通过其他特征组合等价概念?
- 1.特色与偏见,是否真的一概而论,模型是否分得清偏见与特色?
偏见与特色样例:护士是女生(偏见),护士大多是女生(特色)。 - 2.JSD与自蒸馏的优劣势
- 3.在屏蔽某些词语或重新排序后,生成的文本可能会失去原有的语义连贯性和自然表达效果。同时,这个用于屏蔽的子空间可能不够完整。
对抗学习解决偏见
论文
参考论文:Mitigating algorithmic bias in credit scoring support systems through adversarial learning[2026]
发表于:Decision Support Systems[7.7]
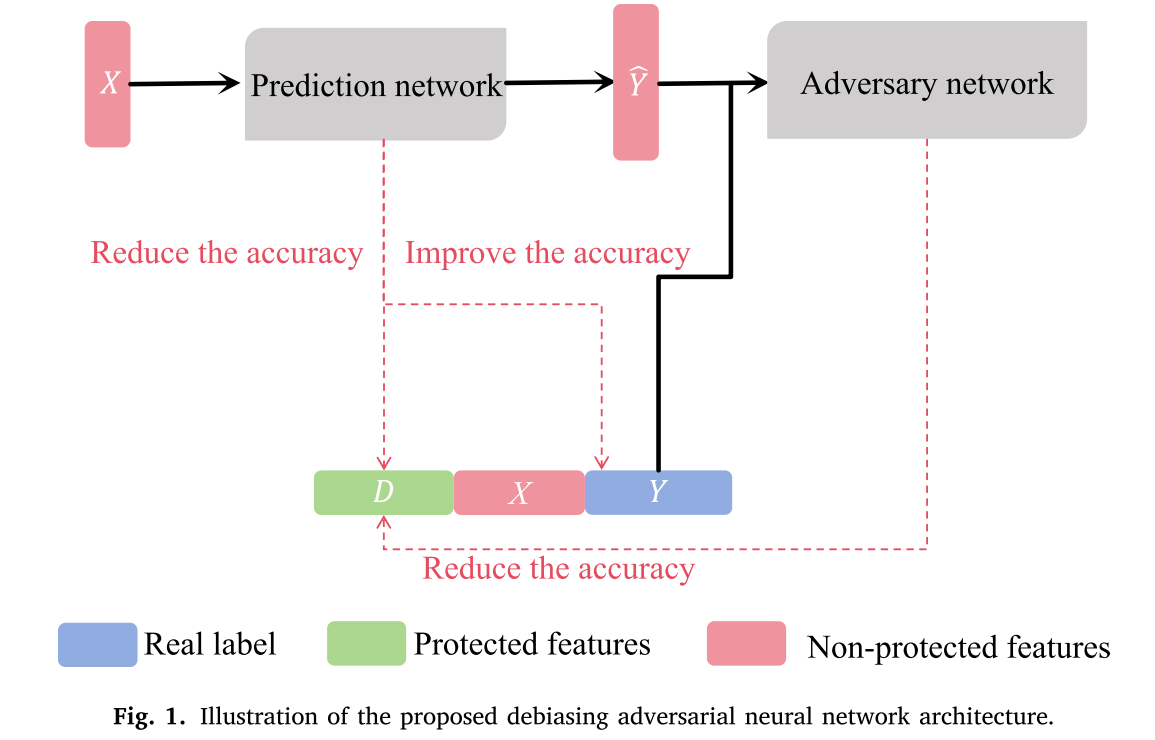
如图所示,该对抗网络通过两个相互博弈的神经网络实现去偏:预测网络(Prediction network)试图从输入数据 \( X \) 中提取特征,一方面准确预测目标标签 \( Y \)(即提高准确率),另一方面要混淆受保护属性 \( D \),使其无法被识别;而对抗网络(Adversary network)则试图从预测网络学到的特征中反向推断出受保护特征(如性别、种族)。通过这种对抗机制,当对抗网络因猜不出 \( D \) 而导致准确率下降时,意味着预测网络在优化过程中已成功剥离了特征中的偏见信息,只保留与任务相关且公平的表征,从而在根源上解决了算法偏见问题。
参考论文:AI-Driven Architectures For Real-Time Fraud Detection And Financial Risk Forecasting: Integrative Frameworks, Adversarial Resilience, And Regulatory Implications In Digital Transaction Ecosystems[2026]
发表于:International Journal of Data Science and Machine Learning[]
对抗学习与自蒸馏优劣势
思考
- 1.这一设计根本思路是剥离特殊特征,是否会导致其他知识/能力遭到损害?
- 2.
自监督与自蒸馏优劣势与自我训练
模型自解毒与自蒸馏
论文
题目:Self-diagnosis and self-debiasing: a proposal for reducing corpus-based bias in NLP【Transactions of the Association for Computational Linguistics】【2023】【6.9】
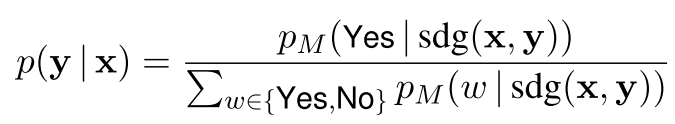
大型语言模型能够执行自我诊断,即仅使用其内部知识和文本描述来判断输出是否存在有毒属性。
为了降低风险,自解毒算法可能会倾向于压制所有带有强烈情感或争议性的词汇,模型输出变得极其乏味、平庸、公式化。
具体做法:分别基于正常文本和带有偏见引导信息的文本下计算对同一个token的预测概率,如果在偏见引导下出现该token的概率更高,说明它很可能是偏见的载体,然后通过缩放函数调低这些词的原始概率。
存在问题
- 1.自去偏见算法可能惩罚了本身无害但在偏见上下文中概率升高的词。作者称之为“过于激进地过滤掉无害词”。
护士与女性,护士可能比较多会出现于女性这个词上下文,但这是社会现象导致的,而不该视为偏见。
- 2.该方法在每一步只考虑已生成的左上下文来决定是否惩罚某个词。一个词在只看左边时可能显得有问题,但结合右边上下文后可能完全无害。Eg:I hate to say this, but you did a great job.
JSD与自蒸馏比较
JSD散度:
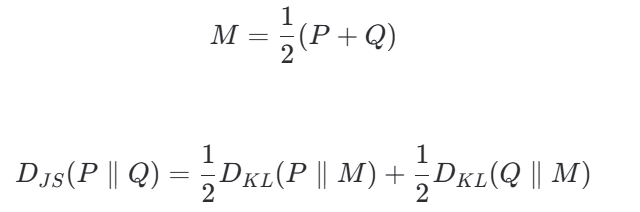
KL散度:

总结:KL散度是以其中一个分布(通常是 \( P \))作为基准来衡量另一个分布的偏移;而JSD是以两者的折中平衡态 \( M \) 作为基准,分别计算两个分布向中间靠拢的代价。
整理思路
自然语言处理的偏见是指模型由于训练数据或算法本身的缺陷而产生的输出偏差。
(训练数据一般指数据集本身存在的偏见,算法指如观察单词共现概率来判断词与词的联系。)
传统解决偏见的方法大多聚焦于模型特征空间的删改、数据集的完善、模型输出的控制。
而以模型为核心的方法则通过提示词工程、强化学习、微调的方法解决。
这些常规解决方法在要求有高质量的真人标注数据集的前提下,为了解决偏见还会额外选择牺牲一定准确性,而且其中针对特征空间的删改的方法还可能损害模型所学习的事实知识。