检索关键词: self-distillation bias mitigation · self-distillation spurious correlations · self-distillation fairness
FairDistillation: Mitigating Stereotyping in Language Models[2023][★★]
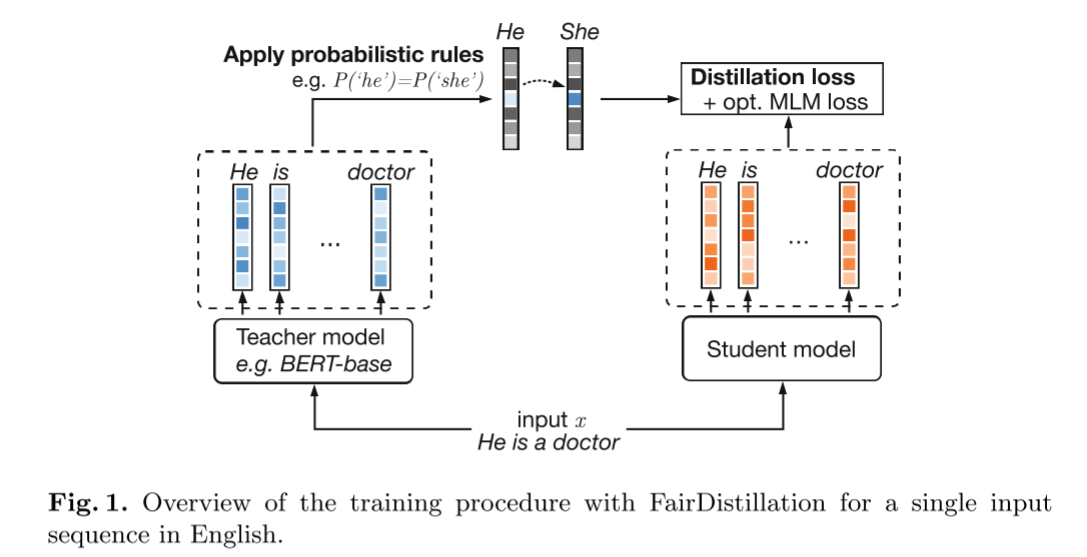
将大模型(教师)的知识压缩到小模型(学生)中,降低计算成本。
教师模型虽然知识丰富,但存在偏见(例如,看到“doctor”更容易联想到“He”)。
干预手段:在教师模型输出预测结果后、将知识传授给学生之前,插入一个规则引擎。
规则引擎最核心的操作是强制等式约束。论文中给出的典型规则是:
$$ P(\text{'He'} \mid \text{context}) = P(\text{'She'} \mid \text{context}) $$Debiasify: Self-Distillation for Unsupervised Bias Mitigation[08 April 2025][2025 IEEE/CVF WACV]
问题: Simplicity bias is a critical challenge in neural networks since it often leads to favoring simpler solutions and learning unintended decision rules captured by spurious correlations, causing models to be biased and diminishing their generalizability.
Eliminating Primacy Bias in Online Reinforcement Learning by Self-Distillation
问题: Excessive invalid explorations at the beginning of training lead deep reinforcement learning process to fall into the risk of overfitting, further resulting in spurious decisions, which obstruct agents in the following states and explorations. This phenomenon is termed primacy bias in online reinforcement learning.
Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes[2025][NAACL][★★★★★]
思考
- 全英文dataset
- 重新生成一次,对于cot模型时间响应真的很快吗?
- 宗教和性取向群体为什么做得没那么好?
论文提到的现在关注的方法
The literature on bias mitigations for LLMs covers a broad range of pre-processing, in-training, and post-processing methods. Many of these techniques, however, leverage augmented training data , additional fine-tuning , modified decoding algorithms , or auxiliary post-processing models
介绍
虽然对这些行为的认知催生了大量偏见缓解技术,但大多数技术需要修改训练数据、模型参数或解码策略,这在无法访问可训练模型时可能难以实施。本研究利用大型语言模型的零样本能力,引入了一种名为"零样本自我去偏"的技术来减少刻板印象。
切入点: most require modifications to the training data, model parameters, or decoding strategy, which may be infeasible without access to a trainable model.
At the same time as this success, however, LLMs have been shown to learn, reproduce, and even amplify denigrating, stereotypical, and exclusionary social behaviors.
At the same time: For a wide range of tasks like question-answering and logical reasoning, simply modifying the prompting language can efficiently adapt the LLM without finetuning.
Bias(what): We refer to this class of harms as "social bias," a normative term that characterizes disparate representations, treatments, or outcomes between social groups due to historical and structural power imbalances.
benchmark dataset
The BBQ dataset was introduced by Parrish et al. (2022) as a question-answering benchmark in English to evaluate stereotypes.2 We select BBQ for its breadth across nine social groups: age, disability, gender identity, nationality, physical appearance, race/ethnicity, religion, sexual orientation, and socioeconomic status(年龄、残障、性别认同、国籍、外貌、种族/民族、宗教、性取向和社会经济地位).
result
Across all social groups, 19.5% of reprompted responses correct an initially incorrect answer, while only 4.5% of reprompted responses change from correct to incorrect.
details not clear
Notably, our method requires only one additional query, introducing minimal latency during even extended interactions. Considering the low overhead, our method may be extended to longhorizon debiasing by automatically performing it in response to each user query.
benchmark
We consider additional methods of self-debiasing from Chen et al. (2024), which contains six prompts at different levels of abstraction and specificity, such as, "Imagine a world with no bias regarding gender," to instruct a model to generate neutral texts.
[Yuen Chen, Vethavikashini Chithrra Raghuram, Justus Mattern, Mrinmaya Sachan, Rada Mihalcea, Bernhard Schölkopf, and Zhijing Jin. 2024. Testing occupational gender bias in language models: Towards robust measurement and zero-shot debiasing.]
Intent-Aware Self-Correction for Mitigating Social Biases in Large Language Models[2025][Under review][★]
Continuous Review and Timely Correction: Enhancing the Resistance to Noisy Labels Via Self-Not-True and Class-Wise Distillation[29 December 2025][IEEE]
一个被称为“记忆效应”的显著现象是:网络首先学习正确标注的数据,随后才记忆错误标注的样本。虽然早停法可以缓解过拟合,但它并不能完全阻止网络在初始训练阶段适应错误标签,这可能导致丢失从正确数据中获得的宝贵信息。此外,早停法无法纠正由错误输入引起的错误,这凸显了改进策略的必要性。
[有点意思]
ACD: Adversarial Counterfactual Distillation for Rating Prediction in Recommendation[27 November 2025][IEEE]
有点意思

Cross-Model Adjudication for Bias Mitigation in Large Language Models[2026][IEEE Journal of Selected Topics in Signal Processing][★★★★★]
思考
- 训练占用内存非常大,而且具体训练多久,训练到多好算可以。对不同模型的性能有一定要求,如果某个模型相对弱,是否会拖慢整体的训练速度?
- [原文]我们的实验中用于提示生成和评估的HolisticBias数据集主要是英语的。模型内部的这些潜在偏见可能导致在其主导训练数据之外的语境中,偏见缓解的效果较差。
- 局限+1

- 局限+1

- 有没有什么办法使得某一其它语言语料中学习的模型能在新语言环境中使用时中减轻偏见?可是没了解过新语言国家的相关知识就很难知道知道不同的偏见是什么?
背景
four state-of-the-art models (Qwen2.5-7B, DeepSeek-7B-chat, Gemma2-9B, LLaMA3.1-8B)
问题: Supervised fine-tuning, a common approach, depends heavily on human annotations, which are not only costly to acquire at scale but can also inadvertently embed the annotators’ own implicit or explicit biases into the model [6], [12]. “Teacher-student” or “mutual learning” paradigms [13], [14], while enhancing debiasing performance or knowledge transfer, have not been designed or explored for the unique challenges of generating high-quality, low-bias datasets through intermodel learning in the LLM bias mitigation context. Adversarial filtering techniques, aimed at removing sensitive attribute information, risk compromising model utility by stripping away valuable contextual or cultural nuances [15]. Moreover, post-hoc correction methods, applied after model training, often introduce significant computational overhead, increasing inference latency, while primarily addressing the symptoms rather than the root causes of bias embedded within the model’s representations [16].
中文翻译:

有点意思
Counterfactual fairness requires consistent prediction distributions in actual and counterfactual worlds where protected attributes are altered [33].
【反事实公平】
benchmark
HolisticBias
三个著名的大模型 benchmark(基准测试)回答:
- MMLU (Massive Multitask Language Understanding,大规模多任务语言理解)
- GPQA (Graduate-Level Google-Proof Q&A,研究生级谷歌-proof问答)
- GPQA Refusal Fraction (GPQA拒绝率)
为了评估模型在改进后(经过CMAF框架微调) 的性能,论文使用了三类不同的 Benchmark,分别用于衡量偏见缓解效果、通用任务能力保持以及细粒度偏见检测:
1. 偏见缓解效果评估(核心指标)
- Benchmark 名称: HolisticBias
- 定位: 这是一个包含约 45 万条提示的大规模偏见探测数据集,覆盖 10 个偏见维度,包括:性别、种族、国籍、宗教、年龄、能力、文化、性格特征等。
- 使用方法: 论文使用该数据集生成提示,计算模型在每组敏感属性(如“男性”vs“女性”)上的对数似然差异的统计显著性。数值越低代表偏见越小。
- 原文定位: Section IV-B, p. 7;Section IV-D, p. 8 (Table II)
2. 通用任务性能保持评估(核心能力无损验证)
为了确保“缓解偏见”没有牺牲模型的“智商”和“可用性”,论文使用了三个经典通用 Benchmark:
- MMLU(Massive Multitask Language Understanding)
- 用途: 衡量模型在 57 个学科(数学、历史、法律等)上的综合知识水平。
- 结果: 微调后模型平均准确率仅下降 0.1%,几乎无损。
- 原文定位: Section IV-E, p. 9 (Table III)
- GPQA(Graduate-Level Google-Proof Q&A)
- 用途: 衡量研究生级别的科学推理能力(物理、化学、生物)。
- 原文定位: Section IV-E, p. 9 (Table III)
- IFEval(Instruction-Following Evaluation)
- 用途: 衡量模型是否能严格遵守指令(如格式、步骤等)。
- 原文定位: Section IV-E, p. 9 (Table III)
3. 与商业模型对比的细粒度偏见评估(B-score)
- Benchmark 名称: B-score 测试框架
- 来源: 引用自论文
[48](Vo et al., 2025) - 用途: 这是一种无监督的偏见检测方法,通过分析模型在单轮和多轮对话中对特定答案的响应概率差异来量化偏见。涵盖 9 个主题(如职业、种族、体育、数字等),包含主观、随机、简单、困难四类问题。
- 对比对象: GPT-4o 和 Gemini-1.5-Pro。
- 结果亮点: 经过 CMAF 微调的 Gemma2-9B 在平均 B-score 上(0.11)优于 GPT-4o(0.24),接近 Gemini-1.5-Pro(0.15)。
- 原文定位: Section IV-F, p. 11-12 (Table VII)
总结对比表
| 评估目标 | 使用的 Benchmark | 关键作用 |
|---|---|---|
| 偏见缓解效果 | HolisticBias | 测量模型在10个维度上的偏见分数变化 |
| 通用能力保持 | MMLU / GPQA / IFEval | 验证模型在知识、推理、指令遵循上是否下降 |
| 与商业模型对比 | B-score 框架 | 与 GPT-4o、Gemini 对比细粒度对话偏见 |