思考
1. SELF-DISTILLATION ENABLES CONTINUAL LEARNING (SDFT) [MIT, 2026]
问题:如何在只有专家演示数据(demonstrations)而无显式奖励函数的情况下,实现模型的持续学习,同时避免灾难性遗忘。
方法:给予教师模型 query(问题)+Demonstration(演示),得到答案概率分布,学生模型的答案概率分布基于 KL 散度去拟合教师模型的答案概率分布。
Demonstration:
- 1. Tool Use: ToolAlpaca 数据集中自带的调用工具解决问题的完整记录。
- 2. Science Q&A: 使用 GPT-4o 为每个问题生成了高质量的思考过程和答案作为演示。
- 3. Knowledge Acquisition: 使用 GPT-5 基于维基百科文章生成了问答对。教师模型的演示是针对具体问题的“包含新事实信息的正确答案”。
- 4. Medical: 临床推理问题的正确医疗答案。
损失:KL 散度。
教师模型:
- 初始化:第 1 行设置教师权重 $\phi$ 等于学生权重 $\theta$。 ("1: Set teacher weights $\phi = \theta$")
- 更新规则:在每个训练步骤的最后(第 19 行),会更新教师参数:$\phi \leftarrow \alpha\theta + (1 - \alpha)\phi$
这表明教师模型是学生模型的慢速移动版本。它追踪学生的进度,但变化更平滑。
Base Model:
| 实验设置 | 使用的模型 |
|---|---|
| 主实验 | Qwen2.5-7B-Instruct |
| 模型缩放研究 | Qwen 2.5 系列:3B / 7B / 14B |
| 推理模型实验 | Olmo-3-7B-Think |
2. SELF-DISTILLATION ENABLES CONTINUAL LEARNING (SDPO) [MIT, 2026]
问题:目前的强化学习(如 GRPO)通常只能拿到一个二值反馈,这在长程推理中会导致严重的「信用分配」问题。此外,如果模型全军覆没(奖励均为 0),学习信号就会消失。
方法:学生模型生成多个候选答案 $y$,送入环境获得反馈 $f$。教师模型根据 $x+f$ 得到概率分布,计算 KL 散度作为损失:
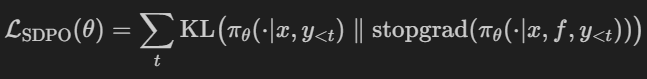
反馈:程序运行结果、错误类型、成功的答案。
教师模型:冻结基本模型不参与参数更新。
3. Self-Distilled Reasoner (OPSD) [2016]
问题:复杂推理任务中搜索空间过大、奖励信号稀疏。在没有外部“强教师”辅助时,模型很难找到深层逻辑路径。
方法:教师模型基于 query 以及正确答案输出分布,学生仅看到 query。衡量每一步推理的损失:
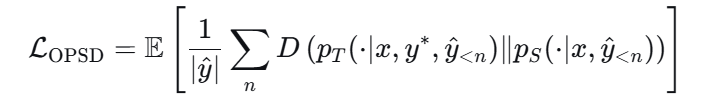
教师模型:固定。
4. CODI: Compressing CoT into Continuous Space [EMNLP, 2025]
问题:如何让 LLM 在不使用自然语言的情况下进行高效的链式推理(CoT)?
方法:教师模型(query+显式 CoT),学生模型(query+隐式 CoT),结合交叉熵+KL 散度。推理时仅使用学生任务,自回归生成固定的连续思维 token,大幅提升速度。
教师模型:与学生模型共享参数,动态更新。
5. Intra-class progressive and adaptive self-distillation [2025]
教师模型:$m$ 轮的学生模型以 $m-1$ 轮的模型作为教师模型。
6. Diffusion Self-Distillation for Zero-Shot Customized Image Generation
问题:如何让 AI 绘画模型既能保持特定主体身份,又能灵活控制新背景/姿态。
$$ \mathcal{L} = \mathcal{L}_{\text{recon}} + \mathcal{L}_{\text{edit}} $$教师模型:固定。Base Model: FLUX1.0 DEV
7. DISD-Net: 多模态情感识别 [IEEE, 2025]
方法:提出动态交互网络。每个单模态分支作为“学生”,模仿完整多模态融合网络(教师)的输出分布。
$$ \mathcal{L} = \mathcal{L}_y + \lambda \mathcal{L}_s + \gamma \mathcal{L}_d + \omega \mathcal{L}_2 $$教师模型:动态更新,Teacher 和 Student 共享同一主干网络。
8. 四种经典自蒸馏方法
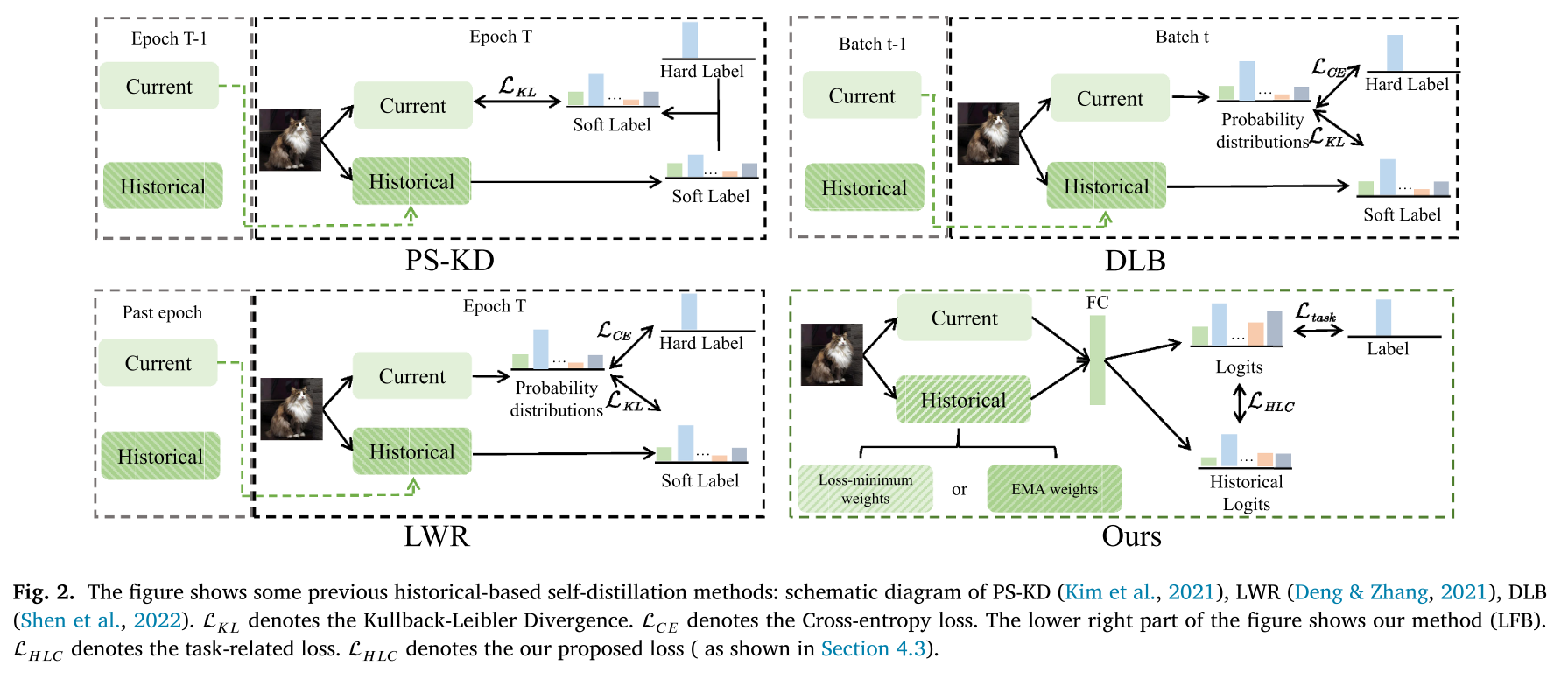
1. PS-KD
用上一个 Epoch 的预测结果教当前模型。损失:交叉熵 + KL。
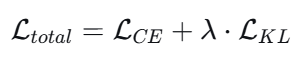
2. LWR (Learning with Retrospection)
用过去所有 Epoch 的预测平均值来教当前模型,信号更稳定。
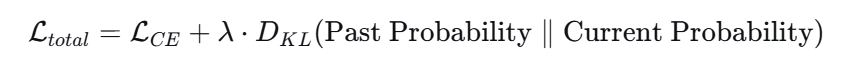
3. DLB
用上一个 Batch 的预测结果教当前 Batch。Batch 层面操作,即时监督。

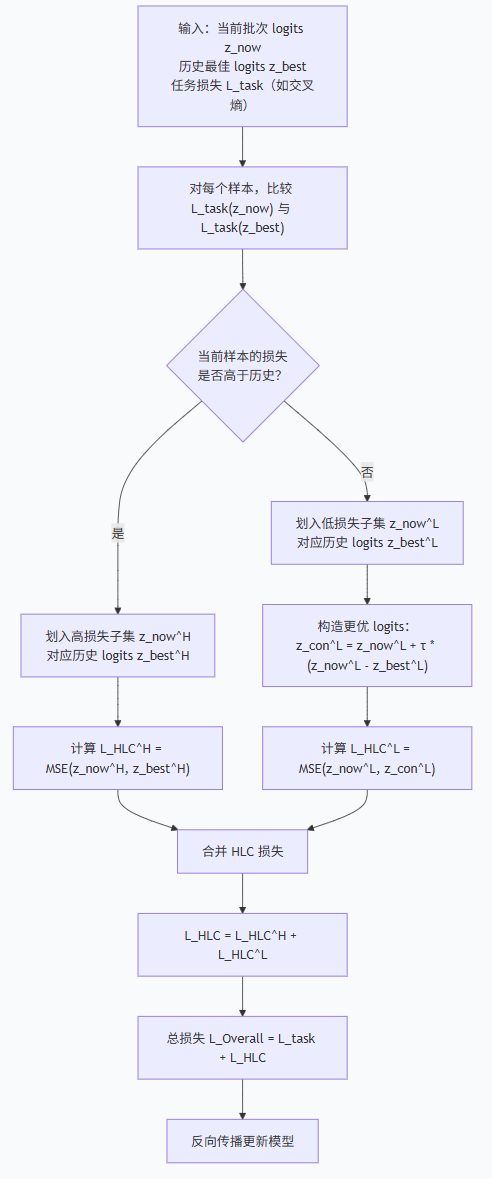
4. LFB (Learn From the Best)
动态挑选“最优”历史模型。提出 HLC Loss,不再是简单的 KL 散度。
9. Unilogit: 机器遗忘 (Machine Unlearning)
方法:构造“遗忘后”的均匀分布。利用反向 KL 散度,迫使遗忘集输出接近均匀分布。
$$ \mathcal{L}_{\text{Unilogit+KL}}(\theta) = \mathbb{E}_{D_f} [\text{KL}(p(y_f|x_f; \theta) \,||\, \tilde{p}(y_f|x_f; \theta))] + \lambda \mathbb{E}_{D_r} [\text{KL}(p(y_r|x_r; \theta_o) \,||\, p(y_r|x_r; \theta))] $$10. Be Your Own Teacher [张林峰]
方法:将 CNN 从前往后切分。让深层部分(老师)指导浅层部分(学生)。浅层部分提前学到抽象特征,提升资源受限设备上的表现。
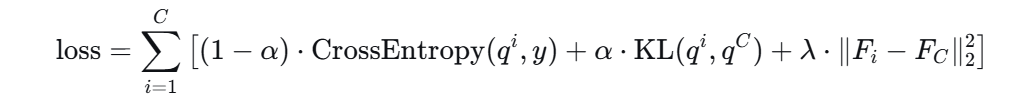
由交叉熵、KL 散度、L2 损失组成。教师模型动态更新。
11. Towards Efficient and Compact Neural Networks [张林峰]
问题:解决教师模型选择困难和训练效率低的问题。在同一个网络的不同深度添加多个浅层分类器,深层指导浅层,实现单阶段自蒸馏。
