理解
self-distillation的出现是为了解决人工标注成本过高的问题。
如何让模型在不断吸收新知识的同时,不丢失已有的核心能力 —— 即「持续学习」,正成为制约大模型进化的关键瓶颈。
1.CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
关注的问题:如何让大语言模型(LLM)在不使用自然语言的情况下,也能进行高效的链式推理(Chain-of-Thought, CoT)?
CODI的具体训练方法
损失公式:
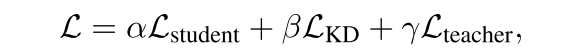
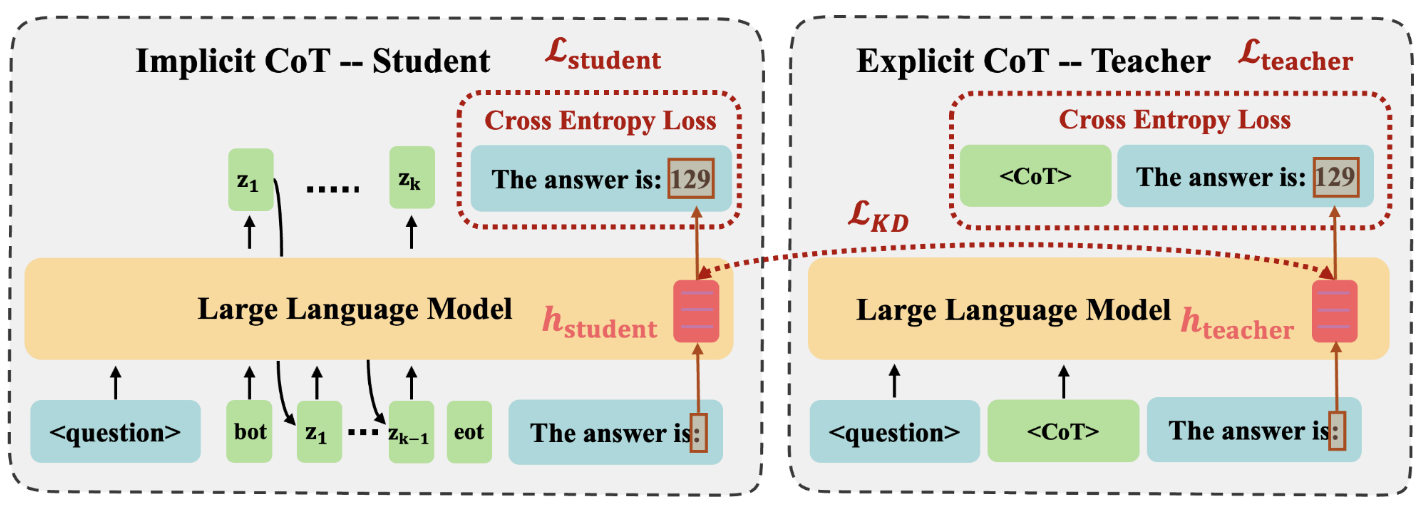
CODI通过联合训练一个教师任务(显式思维链)和一个学生任务(隐式思维链)来实现知识蒸馏,两者共享同一个大型语言模型(LLM)。具体训练流程如下:
- 教师任务(Explicit CoT):输入问题以及人工标注的思维链(Chain-of-Thought)作为真实文本,采用教师强制(teacher forcing)方式,即模型在每一步都使用真实的前缀来预测下一个词,从而生成答案。教师任务的损失函数 $\mathcal{L}_{\text{teacher}}$ 是标准语言建模的交叉熵损失,用于最大化生成文本(包括思维链和最终答案)的概率。
- 学生任务(Implicit CoT):输入仅包含问题,从一个可学习的特殊起始标记
[bot]开始,通过自回归方式逐次生成连续的思维表示(continuous thoughts),最终解码出答案。学生任务同样使用交叉熵损失 $\mathcal{L}_{\text{student}}$ 来优化最终答案的生成,但中间没有显式的语言思维步骤。 - 知识蒸馏(Knowledge Distillation):为了将教师模型的推理能力迁移到学生模型,CODI在每一层的隐藏状态上施加L1损失($\mathcal{L}_{\text{KD}}$),强制学生模型的隐藏状态 $h_{\text{student}}$ 与教师模型的隐藏状态 $h_{\text{teacher}}$ 对齐。由于教师模型在生成过程中利用了真实的思维链,其隐藏状态蕴含了逐步推理的信息,通过对齐,学生模型学会了在连续空间中模拟这种推理过程。
整个训练目标是最小化联合损失:
其中 $\lambda$ 是平衡蒸馏强度的超参数。教师和学生共享模型参数,因此通过反向传播同时更新模型。
- 总结:输入问题以及人工标注的思维链(Chain-of-Thought)。
2.SDFT
- 论文标题:Self-Distillation Enables Continual Learning
- 论文链接:https://www.alphaxiv.org/abs/2601.19897
- 代码链接:https://github.com/idanshen/Self-Distillation
核心机制:该方法假设预训练模型已具备强大的 ICL 潜力。在学习新知识时,首先构造包含少量专家演示(Few-shot)的上下文,诱导模型生成高质量的教师分布;随后要求模型在不带演示的情况下,通过自蒸馏去拟合这一分布。
- 总结:使用few-shot示例得到教师分布。
3.SDPO
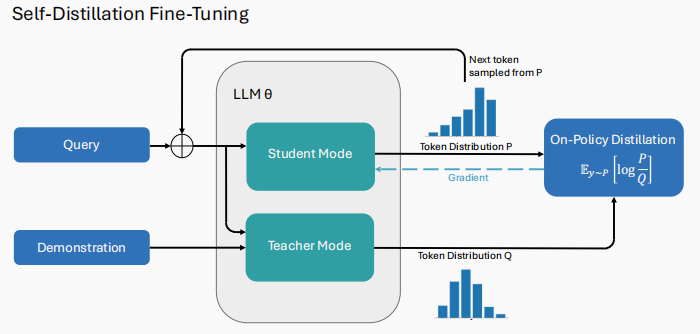
关注的问题:目前的强化学习(如 GRPO)通常只能拿到一个二值反馈,这在长程推理中会导致严重的「信用分配」问题。此外,在 GRPO 等算法中,如果模型在某组尝试中全军覆没(奖励均为 0),学习信号就会消失,导致模型进化停滞。
- 论文标题:Reinforcement Learning via Self-Distillation
- 论文链接:https://arxiv.org/pdf/2601.20802
- 代码链接:https://github.com/lasgroup/SDPO
核心机制:SDPO 引入了 富反馈(Rich Feedback) 环境。当模型生成错误答案时,环境会返回具体的报错信息(如逻辑判读)。模型将这些报错信息重新注入上下文,作为一个 「自省教师」 来重新审视并校准之前的错误尝试。
- 总结:feedback报错信息。
4.OPSD
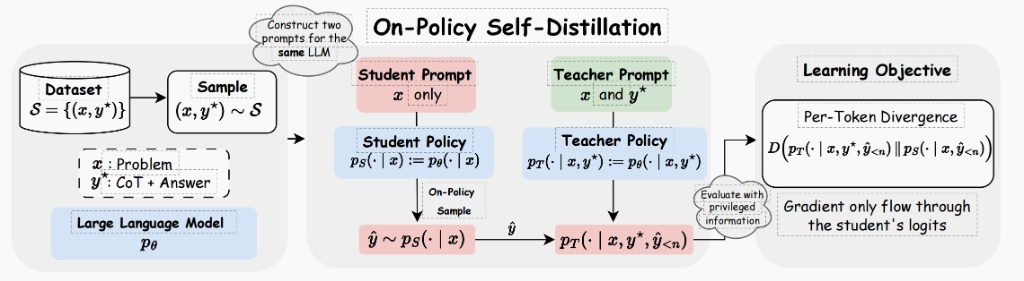
关注的问题:在复杂推理任务中,大模型往往面临搜索空间过大、奖励信号稀疏的问题。尽管强化学习能提升模型上限,但在没有外部 「强教师」 辅助的在线学习场景中,模型很难在短时间内找到通往正确答案的深层逻辑路径。
论文标题:Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
论文链接:https://arxiv.org/pdf/2601.18734
核心机制:该框架将模型配置为两种状态。教师策略在输入中包含 「特权信息」(如标准答案或经过验证的推理轨迹),能够产生高质量的 Token 概率分布;而学生策略则在不接触特权信息的情况下仅凭题目进行作答。
- 总结:query+正确答案得到教师分布。
5.Intra-class progressive and adaptive self-distillation
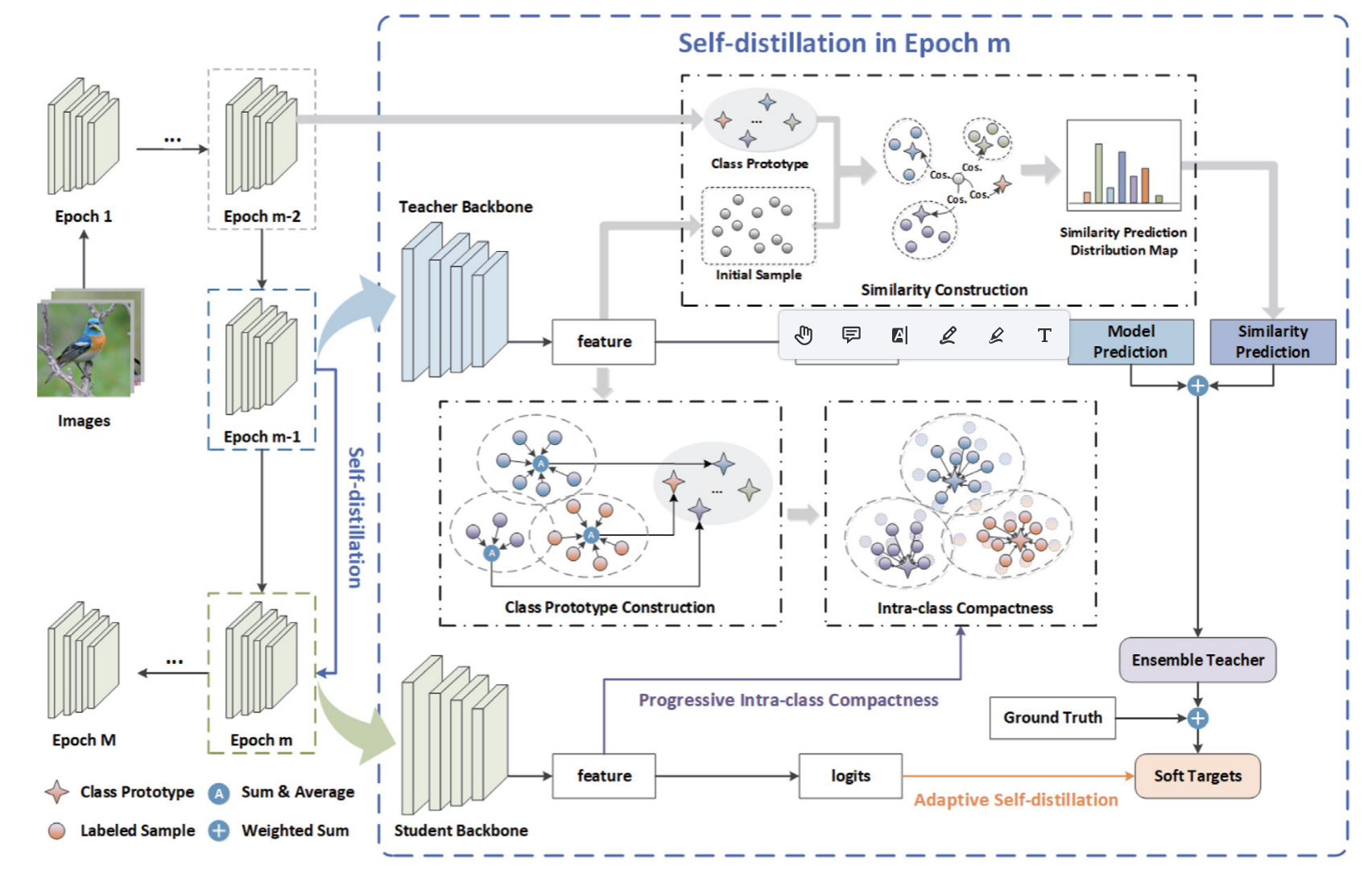
- 类原型(Class Prototype) 是指一个类别在特征空间中的代表性中心向量。
- 在图像识别和深度学习中,Similarity Prediction Distribution Map(相似度预测分布图) 是一个反映“当前样本与各个类别模板(原型)之间有多像”的概率分布。
- Ensemble Teacher(集成教师) 指的是一种“复合型”或“多维度”的导师信号。
传统的蒸馏只有一个教师信号。而图中的 Ensemble Teacher 是由以下两者通过加权求和(Weighted Sum,即图中那个带 + 的蓝色圆圈)融合而成的:
- 分身 A:Model Prediction(模型预测):这是教师模型(第 $m-1$ 轮的模型)最直观的分类结果。它代表了模型根据经验给出的“直觉”判断。
- 分身 B:Similarity Prediction(相似度预测):这是基于特征空间物理距离算出来的分布图(即我们上一个问题讨论的分布图)。它代表了样本与各类别“标准原型”之间的逻辑关联。
- Progressive Intra-class Compactness(渐进式类内紧凑性) 是一个核心概念。
- 创新点: IPASD 增加了一个“相似度预测”分支。它计算当前特征与各个类原型的余弦相似度 (Cos.),生成一个分布图。
自蒸馏训练过程及损失函数的构成
一、 核心数学符号定义
在深入公式前,先明确基本符号:
- $D = \{X, Y\}$:训练数据集,其中 $X$ 是图像,$Y$ 是真实标签(Ground Truth)。
- $m$:当前训练轮次(Epoch),作为**学生**;$m-1$:上一轮模型,作为**教师**。
- $z^T, z^S$:教师和学生网络输出的 **Logits**(分类层前的原始得分)。
- $f^T, f^S$:教师和学生提取的 **特征向量**(Feature vectors)。
- $K$:类别总数;$T$:蒸馏温度系数。
- $y_i$:第 $i$ 个样本的真实标签。
二、 训练过程第一步:类内紧凑性蒸馏 (PICC)
这一步的目标是让同类样本在特征空间中靠拢。
1. 构建类原型 (Class Prototype) —— 公式 (5)
教师模型(第 $m-1$ 轮)提取同类样本特征的平均值作为该类的“模板”:
2. 计算相似度分布 —— 公式 (6) & (8)
计算学生特征 $f_i^S$ 与教师原型 $c_k^T$ 之间的余弦相似度,并转化为概率分布 $u_{i,k}$:
3. 特征损失函数 ($L_{PICC}$) —— 公式 (10)
强制学生的特征向正确类别的教师原型靠拢:
三、 训练过程第二步:自适应自蒸馏 (ASD)
这一步是将“逻辑知识”与“特征知识”融合,自适应地指导学生。
1. 构建集成教师 (Ensemble Teacher) —— 公式 (11) & (12)
模型计算一个权重 $w_i$,动态结合教师的分类预测 $p^T$ 和上面算出的特征相似度分布 $u^T$:
2. 生成软目标 (Soft Targets) —— 公式 (13) & (14)
随着训练进行,模型会越来越“信任”教师。引入动态权重 $\epsilon_m = \epsilon \cdot \frac{m}{M}$($M$ 为总轮数):
动态权重 $\epsilon_m = \epsilon \cdot \frac{m}{M}$($M$ 为总轮数),这一设计很有意思
3. 蒸馏损失函数 ($L_{ASD}$) —— 公式 (15)
学生预测 $p^S$ 与软目标 $s$ 之间的差异:
四、 总结:总损失函数 (Total Loss)
IPASD 的总训练损失是上述两部分的加权结合(见公式 16):
6.Diffusion Self-Distillation for Zero-Shot Customized Image Generation
关注的问题:如何让AI绘画模型既能保持特定主体身份(如某个人、某个物品),又能灵活控制新背景/姿态的难题。
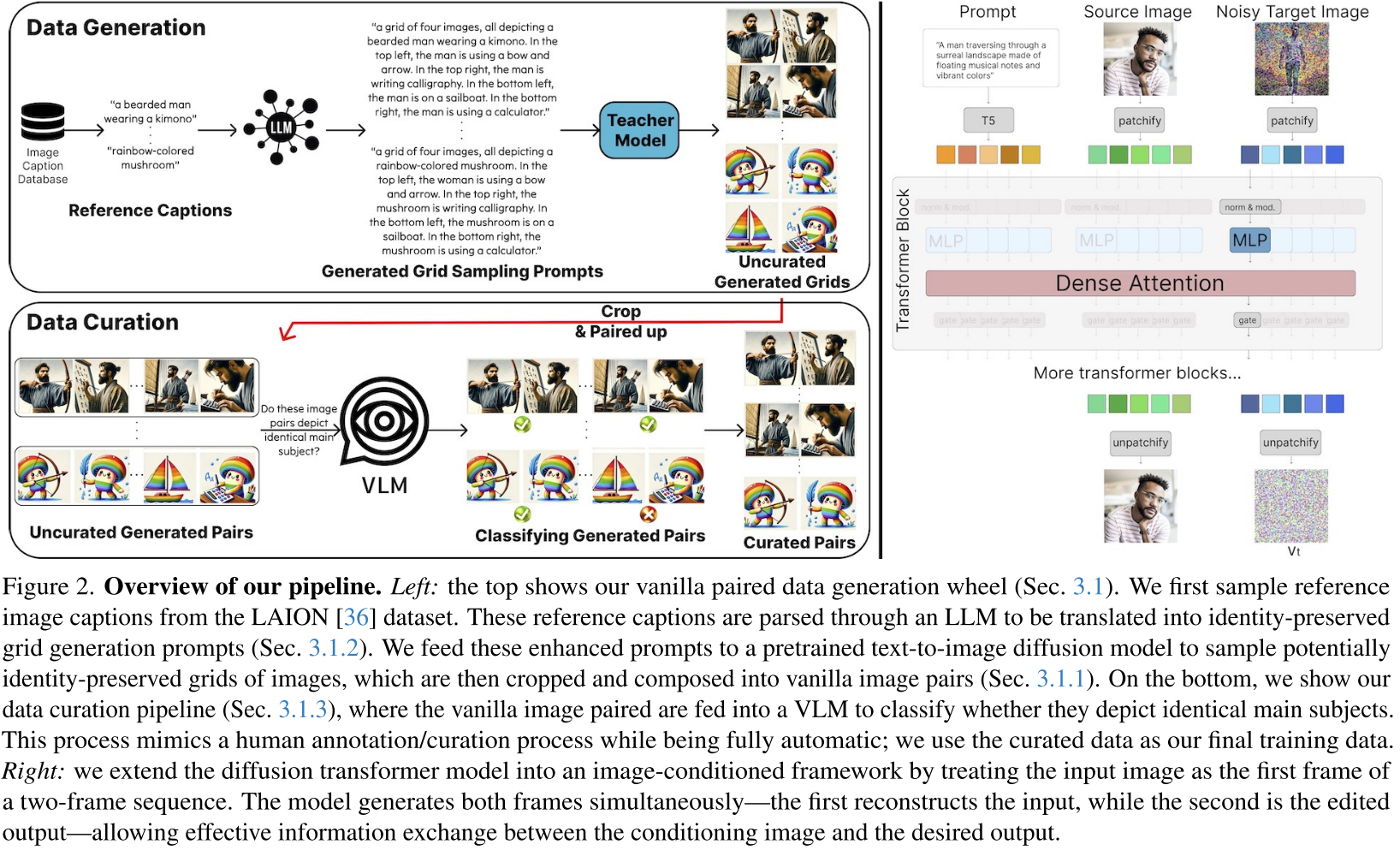
具体架构:
1. 左上部分:数据生成 (Data Generation) —— 创造“教学素材”
训练图像编辑模型最难的是找到“修改前”和“修改后”完全对应的配对图片。该研究通过以下步骤解决:
- 输入:从现有的数据库(如 LAION)中获取简单的描述(Reference Captions),比如“一个穿和服的胡须男”。
- LLM 扩展:利用大语言模型(LLM)将简单描述扩展成复杂的“网格采样提示词(Grid Sampling Prompts)”。它要求生成一张 $2 \times 2$ 的网格图,且明确要求四张图中必须是同一个主体在做四种不同的事。
- 教师模型采样:将这些提示词输入预训练的扩散模型(Teacher Model),生成包含四个场景的网格图。
2. 左下部分:数据筛选 (Data Curation) —— 保证素材质量
- 裁剪与配对 (Crop & Paired up):将 $2 \times 2$ 网格图裁剪成多对“源图-目标图”组合。
- VLM 审核:引入视觉语言模型(VLM,如 GPT-4V 等)。由 VLM 充当“审核员”,判断主体一致性。
- 精选对 (Curated Pairs):只有身份一致性极高的配对才会被留下。
3. 右侧部分:模型架构 (Image-Conditioned Transformer) —— 核心算法
- 双输入序列:模型同时接收文字提示词(Prompt)、源图像(Source Image)和带噪声的目标图像(Noisy Target Image)。
- Patchify(分块):图像被切成一个个小方块。
- 稠密注意力机制 (Dense Attention):关键点。模型在处理目标图像的每一个方块时,都可以通过注意力机制去查看源图像对应的方块。
4.损失函数:
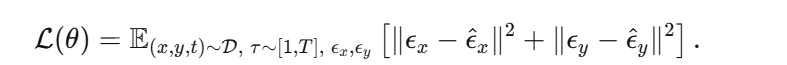
公式结构拆解
1. 期望符号 $\mathbb{E}$ 的含义
该期望覆盖了三个随机变量:样本选择、扩散时间步和随机高斯噪声。训练时,模型要遍历所有图像对,尝试各种加噪程度。
2. 损失函数的两项结构
- 第一项 $\|\epsilon_x - \hat{\epsilon}_x\|^2$:要求模型准确预测参考图像上的噪声。为什么需要? 为了保证模型牢牢记住参考图像的身份信息。
- 第二项 $\|\epsilon_y - \hat{\epsilon}_y\|^2$:要求模型准确预测目标图像上的噪声,从而生成目标图像。
什么是Dense Attention?
Dense Attention(稠密注意力机制) 是相对于“稀疏注意力”的一个概念。在 Transformer 中,设输入序列长度为 $N$:
Dense Attention (稠密注意力)
- 数学定义:每一个 Query 都会与序列中所有的 Key 计算相似度。矩阵 $A = \frac{QK^T}{\sqrt{d}}$ 是一个 $N \times N$ 的全秩稠密矩阵。
- 计算复杂度:$O(N^2 \cdot d)$。
- 物理意义:序列中的每一个像素块(Patch)都能“看到”整个图像的所有其他像素块。
在图中的意义: 确保了目标图中的每一个像素在生成时,都能参考源图中任意位置的细节。这种全域连接是保持物体身份(Identity)不走样的数学保证。
Sparse Attention (稀疏注意力)
只允许 Query 与特定子集的 Key 计算相似度,通过掩码矩阵 $M$ 实现:
复杂度可降低到 $O(N \cdot \log N)$ 或 $O(N \cdot k)$。