想法
让模型在不断吸收新知识的同时,不丢失已有的核心能力。
// 多模态能力迁移?
1. DISD-Net: A Dynamic Interactive Network With Self-Distillation for Cross-Subject Multi-Modal Emotion Recognition【IEEE】
关注的问题:(i)如何同时从多模态数据中学习紧凑且具有代表性的特征;(ii)考虑到个体生物信号的多样性,如何解决受试者间的差异并增强情感识别模型的泛化能力。为此,作者提出了一种用于跨受试者多模态情感识别的带自蒸馏的动态交互网络(DISD-Net)。
DISD-Net 包含一个动态交互模块,用于捕获多模态数据中的模态内和模态间交互。此外,为了增强模态表示的紧凑性,我们利用 DISD-Net 模型生成的软标签作为补充训练指导。这涉及引入自蒸馏,旨在将 DISD-Net 模型包含硬标签和软标签的知识迁移到每个模态。
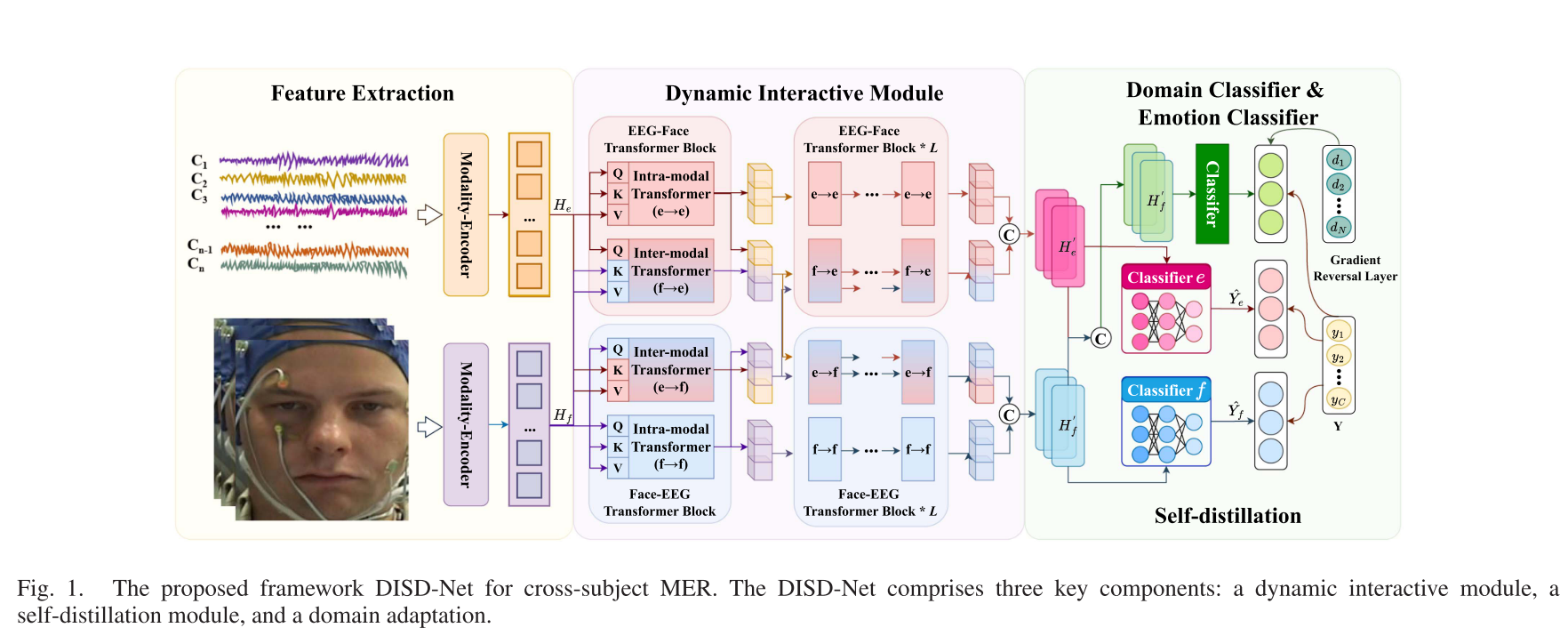
理解:
第一阶段:特征提取
- 输入:原始数据——EEG信号(脑电)和Face signals(面部信号)。
- 处理:数据分别进入各自的 Modality-encoder。
- EEG编码器(对应公式5):提取EEG的时空特征 $G^e$。
- Face编码器(对应公式8):提取面部的注意力增强特征 $G^f$。
- 输出:两个模态的特征向量 $G^e$ 和 $G^f$。
第二阶段:动态交互模块
这是图中最核心的交互区域,输入为 $G^e$ 和 $G^f$:
- Intra-modal Transformer(模态内Transformer):每个模态的特征自己输入给自己(Q=K=V),学习模态内部各个部分之间的关系(例如,EEG信号中前额叶和顶叶区域的关系)。对应公式(9)中的 $H_{e \to e}^{(1)}$ 和 $H_{f \to f}^{(1)}$。
- Inter-modal Transformer(模态间Transformer):这是关键。一个模态的特征作为查询(Q),去另一个模态的特征中检索信息(K,V)。例如,用EEG特征去查询面部特征中对应的部分,学习跨模态的交互信息。对应公式(9)中的 $h_{f \to e}^{(1)}$ 和 $h_{e \to f}^{(1)}$。
- 多层交互:图中展示了多层(Layer 1, Layer 2, ...)的交互过程。第一层的输出会作为第二层的输入,进行更复杂的融合(对应公式13-18)。
- 输出:经过多层动态交互后,得到两个模态最终的交互特征 $H'_e$ 和 $H'_f$(对应公式19-20)。
第三阶段:分类与蒸馏
路径一:多模态融合分类
- $H'_e$ 和 $H'_f$ 会融合(图中在进入GRL前合并),经过 Domain Classifier 和 Emotion Classifier。
- GRL(梯度反转层):这是实现域自适应(DA)的关键。它在反向传播时会将梯度取反,使得特征提取器(Fd)学习到既能让情感分类器准确分类、又能“迷惑”域分类器(让其分不清是哪个被试者)的域不变特征。对应损失 $\mathcal{L}_d$ 和 $\mathcal{L}_y$。
路径二:自蒸馏
- 图中从动态交互模块引出两条线,分别连接 c1(学生1,EEG单模态分支)和 c2(学生2,Face单模态分支)。
- 这两个学生分支尝试预测情感标签,预测结果 $\hat{Y}_e$ 和 $\hat{Y}_f$ 与真实标签 $Y$ 计算损失 $\mathcal{L}^e_s$ 和 $\mathcal{L}^f_s$。
- 知识流动:完整的DISD-Net(包含融合特征的主分类器)作为“教师”,通过总损失的反向传播,将包含跨模态交互的知识“蒸馏”到这两个单模态学生分支中。
最终损失:

总结:多模态中,学生模型变为两个,教师模型是从整体出发获取分布,每个“学生”(单模态分支)不仅学会预测正确的标签(硬标签),还要学会模仿“教师”(完整的多模态网络)的输出分布(软标签)。
2. Self-Distillation: Towards Efficient and Compact Neural Networks【IEEE】
为什么自蒸馏可以尽可能让模型在不断吸收新知识的同时,不丢失已有的核心能力?
自蒸馏帮助模型收敛到“平坦最小值”,这种最小值对参数扰动和数据偏差不敏感,从而使得模型在吸收新知识(如训练过程中多个分类器的联合优化)时,不会丢失已有的核心能力,反而增强了模型的泛化能力和稳定性。这正是自蒸馏能够在不遗忘旧知识的前提下提升模型性能的关键原因。
3. Learn from the best: A universal self-distillation approach with historical logits
模型权重是什么
在代码层面,模型权重就是一堆数字。比如一个极简单的模型:
# 一个只有两层的极简模型
model_weights = {
'layer1.weight': [[0.23, -0.45, 0.12], [0.56, 0.78, -0.34]], # 矩阵
'layer1.bias': [0.1, -0.2], # 向量
'layer2.weight': [[0.67, -0.89]], # 矩阵
'layer2.bias': [0.05] # 标量
}训练中后期:指数移动平均(EMA)权重
EMA不是某一次的权重,而是历史权重的加权平均。公式是:
其中 $\beta$ 通常取 0.999。
Logits
结合我们之前讨论的上下文,历史 Logits 是 LFB 论文中提出的一个核心概念。简单来说,它是指由“最佳历史模型权重”生成的、当前样本在过去某个最优时刻的原始预测值。
1. 什么是 Logits?(复习)
- 它是模型最后一层输出的、未经 Softmax 归一化的原始分数。
- 它比概率包含更丰富的信息,比如能看出模型认为“猫”和“狗”的相似度比“猫”和“汽车”更高。
2. 什么是“历史 Logits”?
在 LFB 的框架里,“历史 Logits”特指:将当前输入的样本,喂给“最佳历史模型权重”后,由该模型计算出来的 Logits 值。
- 当前 Logits:当前正在训练的模型,对输入样本 x 的预测结果。
- 历史 Logits:最佳历史模型(由损失最小或 EMA 权重构成),对同一个输入样本 x 的预测结果。
3. 历史 Logits 是如何产生的?
- 选出一个“最佳历史模型”:挑出一套最优的模型权重 ($\theta_{best}$)。这套权重被固定下来,专门用来做“老师”。
- 共享分类器:这个历史模型和当前模型共享同一个线性分类层(FC层)。
- 前向传播:将同一个输入样本 x,分别送入当前模型和历史最佳模型,得到 $z_{now}$ 和 $z_{best}$。
4. 历史 Logits 在 LFB 中长什么样?
| 类别 | 当前 Logits (当前模型) | 历史 Logits (最佳历史模型) | 概率对比 (Softmax后) |
|---|---|---|---|
| 猫 | 5.8 | 6.2 | 历史模型更有把握 |
| 狗 | 2.1 | 1.5 | 历史模型认为更像猫 |
| 鸟 | -0.5 | -0.8 | (差异较小) |
其他
| 阶段 | 用谁 | 为什么 |
|---|---|---|
| 训练初期 | 损失最小权重 | 模型在快速下降期,损失最小代表找到了正确方向,需要激进地加速 |
| 训练中后期 | EMA权重 | 模型接近收敛,损失最小可能只是偶然跳进了一个深坑,需要稳健的引导 |
总结:前x个训练轮的模型用损失最小的,剩余轮次用指数移动平均(EMA)求得的模型权重。
4. 多个自蒸馏方法记录对比
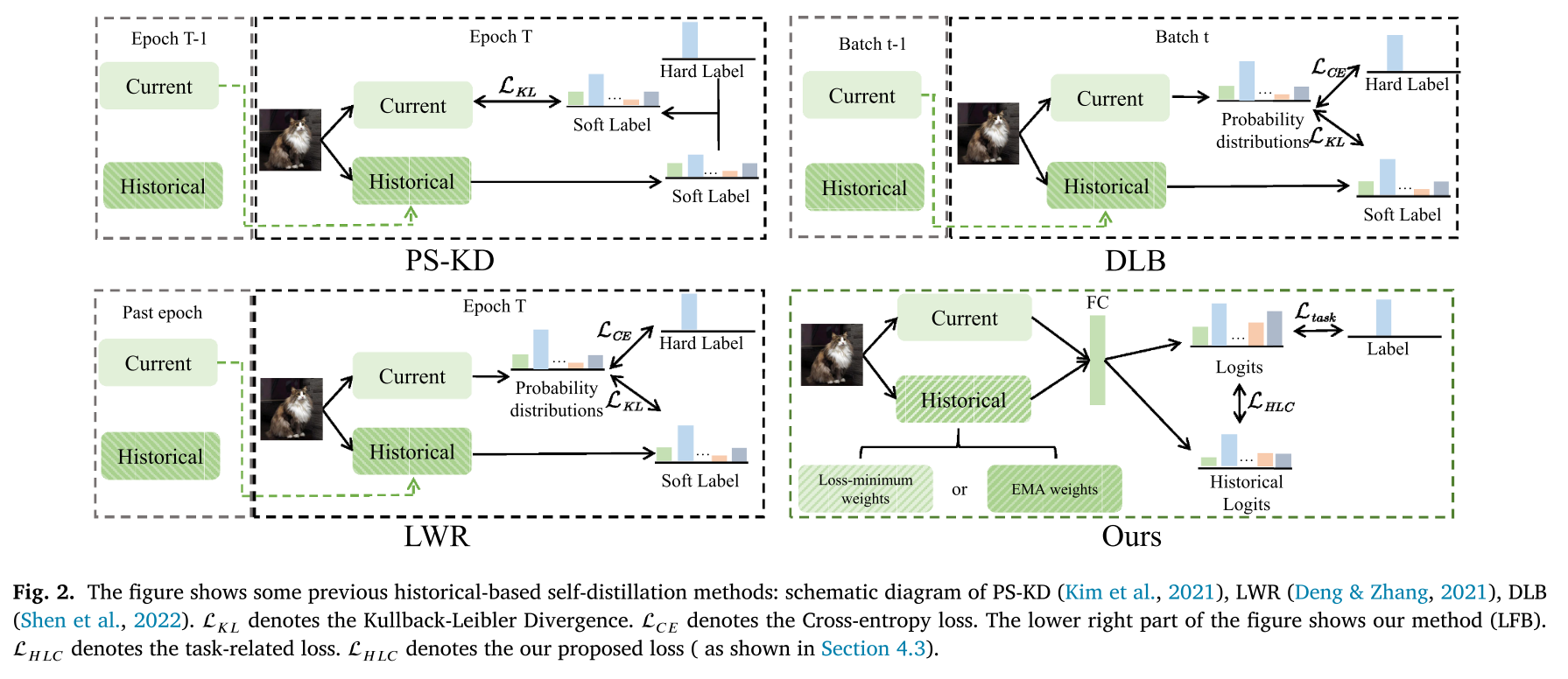
这张图非常直观地展示了四种基于历史数据的自蒸馏方法的流程对比:
1. PS-KD (Progressive Refinement of Targets)
- 核心逻辑:用上一个Epoch的预测结果来教当前Epoch的模型。
- 监督信号:上一个周期(Epoch T-1)的预测概率分布 $P^{T-1}$ 作为软标签。
- 特点:基于周期的时间集成,缺点是错误知识可能传递。
2. LWR (Learning with Retrospection)
- 核心逻辑:用过去所有Epoch的预测平均值来教当前模型。
- 监督信号:历史所有周期预测结果的移动平均 $\bar{P}$。
- 特点:通过平均获得更稳定的教师信号。
3. DLB (Self-Distillation from the Last Mini-Batch)
- 核心逻辑:用上一个Batch的预测结果来教当前Batch的模型。
- 特点:Batch层面操作,提供即时监督,但训练初期波动大。
4. LFB (Learn From the Best)
- 核心逻辑:动态挑选整个训练过程中“最优”的历史模型来教当前模型。
- 监督信号:由最佳历史权重(损失最小或EMA)生成的历史Logits。
- 损失函数:使用 HLC损失,动态区分样本好坏。
总结对比
| 方法 | 教师是谁? | 监督信号 | 核心逻辑 |
|---|---|---|---|
| PS-KD | 上一个Epoch的自己 | 上周期概率分布 | 学习“最近的自己” |
| LWR | 所有历史Epoch的平均 | 历史平均概率分布 | 学习“平均的自己” |
| DLB | 上一个Batch的自己 | 上一批次概率分布 | 学习“即时的自己” |
| LFB (Ours) | 最优的历史自己 | 由最佳权重生成的Logits | 学习“最好的自己” |
交叉熵与KL散度
交叉熵 = KL散度 + 真实分布的熵
具体来说:
其中:
- $H(P, Q)$ 是交叉熵
- $D_{KL}(P||Q)$ 是KL散度
- $H(P)$ 是真实分布的熵(对于固定标签是常数)