在复杂的神经网络模型中,如何有效地融合不同组件(如注意力头)的信息是一个关键问题。门控网络提供了一种动态的解决方案。
1. 怎么做的? (具体架构与实现)
核心概念: 这个门控网络本质上是一个 双层多层感知机(Two-layer MLP),它的输入是所有注意力头输出的拼接,输出是每个头的权重。
论文中定义的公式如下(以 T3Time 模型为例):
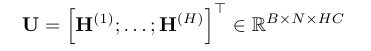
具体的架构流程如下:
-
输入层 (Collection):
首先,模型将所有 $H$ 个注意力头(Heads)的输出结果 $\mathbf{H}^{(h)}$ 拼接在一起。此时输入向量 $\mathbf{U}_{b,n}$ 的维度是 $H \times C$(即:头的数量 $\times$ 每个头的特征维度)。 -
第一层线性变换 (Compression):
使用参数矩阵 $\mathbf{W}_5 \in \mathbb{R}^{128 \times HC}$。将输入维度从 $HC$ 压缩到隐层维度 128。这一步旨在提取联合特征。 -
层归一化与激活 (Norm & Act):
应用 Layer Normalization (LN) 对这 128 个特征进行归一化,随后通过 ReLU ($\phi$) 引入非线性激活函数,增强模型的表达能力。 -
第二层线性变换 (Scoring):
使用参数矩阵 $\mathbf{W}_6 \in \mathbb{R}^{H \times 128}$。将 128 维映射回 $H$ 维。这里的 $H$ 个数值对应每个头的原始分数(Logit)。 -
Softmax (Probability):
对输出的 $H$ 个数值应用 Softmax 函数,确保所有头的权重之和为 1,形成最终的概率分布。
2. 有什么用? (设计目的)
传统的 Transformer 在处理多头注意力时,通常是简单地将所有头的输出拼接起来,然后通过一个线性层混合(或者直接平均)。这种做法是“静态”的——无论输入数据是什么样子,模型融合各个头的方式都是固定的。
这个门控网络的作用是:
实现“按需分配”和“因地制宜”。它让模型能够根据当前具体的输入数据(每个变量的特征),动态地判断哪一个注意力头(Head)提取的信息更有价值,从而赋予它更高的权重。类似于大脑在处理不同任务时会激活不同的区域。
3. 举例
为了更直观地理解,我们来看一个具体的场景。
背景:假设我们在预测 “电力系统”,模型设置了 2 个注意力头 (Head 1, Head 2)。
输入数据中有两个变量:“工业用电量” 和 “居民用电量”。
- ⚡ Head 1:擅长捕捉“突发事件”(比如 LLM 提示词里说“今天有极端高温”)。
- 🔄 Head 2:擅长捕捉“周期规律”(比如“周一到周五是高峰”)。
⛔ 如果没有门控网络(传统做法):
模型会把 Head 1 和 Head 2 的结果各占 50% 混合,或者以固定的比例混合,无法区分变量特性。
✅ 有了门控网络(T3Time的做法):
工厂运作非常规律,受高温影响较小。门控网络读取数据后,发现 Head 2 的周期信息更准。
👉 打分结果: Head 1 (突发) = 10%,Head 2 (周期) = 90%。
👉 结果: 预测主要依赖周期规律。
居民对气温非常敏感,一热就开空调。门控网络结合 LLM 的高温提示,发现 Head 1 的信息至关重要。
👉 打分结果: Head 1 (突发) = 80%,Head 2 (周期) = 20%。
👉 结果: 预测重点捕捉了高温带来的激增,而不是死板地照搬上周数据。
总结: 同样的两个头,针对不同的变量,门控网络自动给出了截然不同的融合策略,这就是“自适应”的威力。