PPO 是经典的强化学习算法,通过旧策略采样轨迹来估计新策略的梯度,这种方法必须保证新、旧策略分布差距不大,否则,估计新策略的梯度会失准,会使用 hard-clipping 技巧,避免新、旧策略分布差距过大,PPO公式如下:
对于此公式理解如下:
1. $L^{\text{CPI}}$ | CPI(保守策略迭代)
其中策略梯度公式为:
PPO中第一部分要介绍的是:`CPI(保守策略迭代)`,这是一种策略优化的方法。`它的目标`是让新的策略($\pi_\theta$)和旧的策略($\pi_{\theta_{\text{old}}}$)之间的变化尽可能小。这样做的好处是可以让策略更新更加稳定,避免因为变化太大而导致性能突然变差。
$\frac{\pi_{\theta}(o_t \mid q, o_{\lt t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{\lt t})}$ 指的是新策略 $\pi_\theta$ 选择动作q的概率与旧策略 $\pi_{\theta_{\text{old}}}$ 选择`相同动作`的概率之比。
$\hat{A}_t$ 是策略梯度中的优势函数,表示当前动作q相对于旧策略q的概率。
$\hat{A}_t$ 的计算方法看另一篇博客。
但是,如果没有任何限制地去最大化CPI的目标函数($L^{\text{CPI}}$),就会导致策略更新变得过大。这是因为`CPI的目标函数只考虑了新旧策略之间的相似性,而没有考虑到策略更新后的性能提升。`
举例理解:
- 假设你有一个机器人,它的任务是学会走路。旧的策略($\pi_{\theta_{\text{old}}}$)是机器人一步一步地慢慢走。新的策略($\pi_\theta$)是机器人尝试跑起来。
- 如果没有限制地去最大化CPI的目标函数,那么新的策略($\pi_\theta$)就会尽可能地接近旧的策略($\pi_{\theta_{\text{old}}}$),也就是让机器人继续一步一步地慢慢走,而不是尝试跑起来。这样做虽然可以让策略更新更加稳定,但是机器人就无法学会跑起来,性能也就无法得到提升。
为了避免这种情况,需要对CPI的目标函数进行修改,加入一个限制条件,使得策略更新既不会过大,又能够带来性能的提升。这就是CLP(保守策略学习)的目标函数($L^{\text{CLIP}}$)所做的事情。
2. $L^{\text{CLIP}}$
算式为:
公式中的 $\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)$ 是一个限制函数,它确保 $r_t(\theta)$ 的值在 $1-\epsilon$ 和 $1+\epsilon$ 之间。这样,策略更新就不会太大。
其中 epsilon ($\epsilon$) 是超参数。目标函数为 $L_{CPI}$ 与剪切目标的期望的最小值。剪切目标的取值特点如下图:
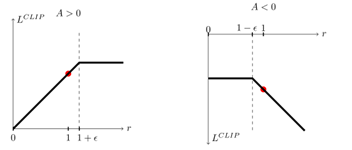
图中展示了 $L^{CLIP}$ 如何随着 $r$ 的变化而变化:
- 当 $A > 0$ 时(即选择的动作比平均情况更好),$L^{CLIP}$ 随着 $r$ 的增加而增加,直到 $r$ 达到 $1 + \epsilon$,之后 $L^{CLIP}$ 不再增加。
- 当 $A < 0$ 时(即选择的动作比平均情况更差),$L^{CLIP}$ 随着 $r$ 的减少而减少,直到 $r$ 达到 $1 - \epsilon$,之后 $L^{CLIP}$ 不再减少。
通过使用PPO,可以确保智能体在尝试新策略时不会偏离旧策略太远,从而避免性能突然变差。这种方法可以帮助智能体在保持稳定性的同时,逐步优化策略,使其更加高效。
3. PPO 训练流程
- 采样轨迹 (Rollout): 通过模型生成当前批次 prompt 的 response;
- 奖励计算 (Reward): 对生成的 response 进行 sequence-level reward 计算(可通过 Reward model 预测或基于规则的方式计算奖励);
- 计算Value: Value Model 估计每个response token的价值 (Value),即截止到当前response token,未来生成完整个response的期望奖励回报估计;
- 计算token-level advantage: 通过 GAE (Generalized Advantage Estimation, 算法如下) 分配 advantage 给每个 token,形成 token-level 的监督信号;
$$ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t), \quad \hat{A}_t = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}. \quad (1) $$
- Value Model 梯度更新;
- 策略梯度更新。
4. Adaptive KL Penalty Coefficient
其实就是在策略梯度算式部分后面直接再减掉一个 KL散度惩罚项。
至于为什么在策略梯度的算式部分后面可以直接减掉一个KL散度惩罚项的原因是:
这个算式的最终目标是找到最大值(Maximize)。如果KL散度过大(即新旧策略差异很大),会导致目标函数值变小。因此,为了最大化目标函数,算法会主动保证KL散度偏小,而这也对应了让新策略与旧策略步伐变小的核心要求。
5. 其他
SGD
SGD是 “随机梯度下降” (Stochastic Gradient Descent) 的缩写。
什么是SGD?
想象一下,你在一片高低不平的山地上,你的目的是找到这片山地的最低点。如果你从山顶开始,每次只走一小步,并且每一步都朝着当前位置最陡峭的下坡方向走,最终你就能到达最低点。
SGD的原理就是这样:它通过不断调整模型参数,朝着减少损失的方向逐步优化模型。