流形学习(Manifold Learning)
数据降维问题
在很多应用中,数据的维数会很高。以图像数据为例,我们要识别32x32的手写数字图像,如果将像素按行或者列拼接起来形成向量,这个向量的维数是1024。高维的数据不仅给机器学习算法带来挑战,而且导致计算量大,此外还会面临维数灾难的问题(这一问题可以直观的理解成特征向量维数越高,机器学习算法的精度反而会降低)。人所能直观看到和理解的空间最多是3维的,为了数据的可视化,我们也需要将数据投影到低维空间中,因此就需要有数据降维这种算法来完成此任务。
最经典的数据降维算法要数PCA(主成分分析),这是一种线性降维算法,而且是无监督的,它通过线性变换将样本投影到低维空间中:
$$y = Wx$$
其中,$x$是输入向量,$n$为向量,$W$是$m$行$n$列的投影矩阵,将$x$左乘它,可以得到一个$m$维的结果向量$y$。一般情况下,$m$远小于$n$,这样就将一个向量变换成另外一个更低维的向量,从而完成数据降维。PCA的矩阵$W$是通过样本学习得到的,其依据是最小化重构误差。
PCA是一种线性降维技术,对于非线性数据具有局限性,而在实际应用中很多时候数据是非线性的。此时可以采用非线性降维技术,它们都通过一个非线性的映射函数将输入向量$x$映射成一个更低维的向量$y$:
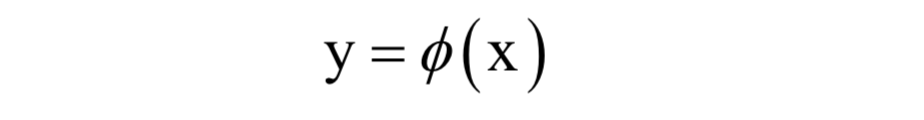
(请将此处的图片源替换为您的 image.png)
假设有一个N维空间中的流形M,即M为N维欧氏空间的一个真子集:
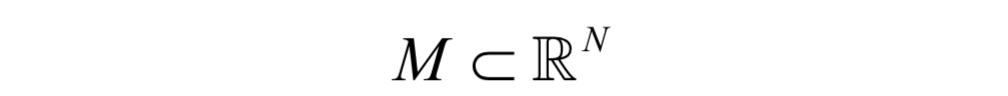
(请将此处的图片源替换为您的 image-1.png)
欧氏空间是以古希腊数学家欧几里得(Euclid)命名的,它是对我们感知的物理空间最自然的数学抽象。
- 直观上:它是我们日常生活经验中的空间。在二维中,它是平坦的纸面;在三维中,它是我们生活的立体世界。其核心特征是平直性(Flatness)。
- 数学上:它是一个赋范向量空间(Normed Vector Space),具体来说,是配备了欧几里得范数(即距离度量)的实向量空间 $\mathbb{R}^n$。
流形学习降维算法要实现的是如下映射:
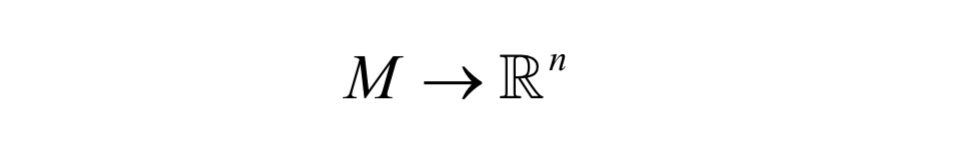
(请将此处的图片源替换为您的 image-2.png)
流形降维算法
下面介绍几种典型的流形降维算法,包括局部线性映射,拉普拉斯特征映射,局部保持投影,等距映射。
局部线性映射 (LLE)
局部线性嵌入(简称LLE)的核心思想是每个样本点都可以由与它相邻的多个点的线性组合(体现了局部线性)来近似重构,这相当于用分段的线性面片近似代替复杂的几何形状,样本投影到低维空间之后要保持这种线性重构关系,即有相同的重构系数。
假设数据集由 $I$ 个 $D$ 维向量 $x_i$ 组成,它们分布在 $D$ 维空间中的一个流形附近。每个数据点和它的邻居位于或者接近于流形的一个局部线性片段(平面,体现了线性,类似于微积分中的以直代曲的思想)上,即可以用邻居点的线性组合来重构,组合系数刻画了局部面片的几何特性:
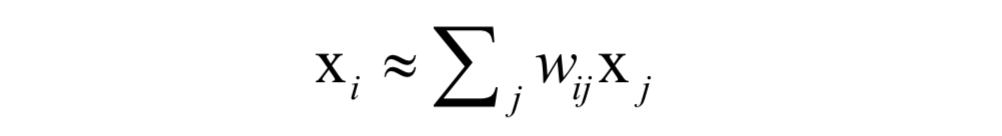
(请将此处的图片源替换为您的 image-3.png)
对于此公式:
- $x_i$:是我们想要表示的目标点(数据点)。
- $x_j$:是 $x_i$ 的邻居点(通常是距离最近的 $k$ 个点)。
- $w_{ij}$:是权重(即重构系数)。
- - “重构”在这里等同于“线性表示” (Linear Representation)。
- - 它的核心假设是:虽然整个数据流形(Manifold)可能是弯弯曲曲的(非线性的),但是在极小的局部范围内(Local),它看起来是平坦的(线性的)。既然是平坦的,那么中间的那个点,就可以用周围几个点通过简单的加法和乘法(线性组合)计算出来。
权重 $w_{ij}$ 为第 $j$ 个数据点对第 $i$ 个点的组合权重,这些点的线性组合被用来近似重构数据点 $i$。 权重系数通过最小化下面的重构误差确定:
$$ \min_{w_{ij}} \sum_{i=1}^{l} \left\| \mathbf{x}_i - \sum_{j=1}^{l} w_{ij} \mathbf{x}_j \right\|^2 $$
在这里还加上了两个约束条件:每个点只由它的邻居来重构,如果 $x_j$ 不在 $x_i$ 的邻居集合里则权重值为 0,这体现了局部性。另外限定权重矩阵的每一行元素之和为 1,即:
$$ \sum_{j} w_{ij} = 1 $$
在获取权重系数之后,就可以将数据点投影到低维空间中。
在这一步,我们的已知条件和未知量发生了翻转:
- 已知:权重矩阵 $W$(已经在上一步计算出来了,代表了点与点之间的局部几何关系)。
- 未知:低维坐标 $Y = \{y_1, y_2, ..., y_N\}$(我们想要得到的结果)。
1. 优化目标函数
我们的目标是找到一组 $y_i$,使得它们依然保持原来的重构关系。也就是要最小化下面的损失函数 $\Phi(Y)$:
$$\Phi(Y) = \sum_{i=1}^{N} \left\| y_i - \sum_{j=1}^{N} w_{ij} y_j \right\|^2$$
第一步:理解 $Y$ 和 $W$ 的形状
为了写成矩阵形式,我们需要明确矩阵长什么样:
$Y$ (坐标矩阵):我们将所有样本的坐标拼成一个大矩阵。通常在 LLE 推导中,为了方便,$Y$ 被定义为 $d \times N$ 的矩阵($d$ 是低维维度,$N$ 是样本数)。 $Y = [y_1, y_2, \dots, y_N]$ 其中每一列就是一个样本 $y_i$。
$W$ (权重矩阵):是一个 $N \times N$ 的矩阵。 $$W = \begin{pmatrix} w_{11} & w_{12} & \dots & w_{1N} \\ w_{21} & w_{22} & \dots & w_{2N} \\ \vdots & \vdots & \ddots & \vdots \\ w_{N1} & w_{N2} & \dots & w_{NN} \end{pmatrix}$$ 注意:$w_{ij}$ 表示 $j$ 对 $i$ 的贡献。
第二步:推导核心项 $\sum_{j} w_{ij} y_j$
在此想用矩阵乘法一次性算出所有样本的“重构值”(即 $\hat{Y}$)
$Y$ 是 $(d \times N)$, $W^T$ 是 $(N \times N)$,其第 $i$ 列是 $(w_{i1}, w_{i2}, \dots, w_{iN})^T$。
$$Y W^T = [y_1, \dots, y_N] \begin{pmatrix} w_{11} & \dots & w_{N1} \\ \vdots & \ddots & \vdots \\ w_{1N} & \dots & w_{NN} \end{pmatrix}$$
可以发现,$Y W^T$ 的第 $i$ 列(对应第 $i$ 个样本的重构值)就是: $$(Y W^T)_i = y_1 w_{i1} + y_2 w_{i2} + \dots + y_N w_{iN} = \sum_{j=1}^{N} w_{ij} y_j$$
第三步:代入损失函数
现在的目标是让“真实值”减去“重构值”。
真实值矩阵:$Y$
重构值矩阵:$YW^T$
那么,误差矩阵 $E$ 就是: $$E = Y - YW^T$$ 我们的损失函数 $\Phi(Y)$ 是所有误差向量长度的平方和。在矩阵代数中,一个矩阵所有列向量的 L2 范数平方和,通常写为 Frobenius 范数的平方(虽然这里符号简写为 $\| \cdot \|^2$,但在推导中含义一致)。 所以: $$\Phi(Y) = \| Y - YW^T \|^2$$
第四步:提取公因式(关键的一步)
根据矩阵分配律,$A(B+C) = AB + AC$。 我们可以把 $Y$ 提出来: $$Y - YW^T = Y(I - W^T)$$ 但是这里给出的公式里是 $Y(I-W)^T$,而前面推导出的是 $Y(I-W^T)$。 这里利用了转置的性质:$(A - B)^T = A^T - B^T$,且 $I^T = I$。 所以: $$(I - W)^T = I^T - W^T = I - W^T$$ 因此: $$Y(I - W^T) \text{ 完全等价于 } Y(I - W)^T$$
$Y$ 的身份是什么?
在 LLE 算法的第三步中:
- $X$ (高维数据):是已知量(比如你输入的 1000 张图片像素数据)。
- $W$ (权重):是已知量(也就是刚才第二步算出来的系数)。
- $Y$ (低维坐标):是未知量(Variables)!这正是我们要通过算法去求出来的东西。
3. 约束条件
为了防止得到无意义的解(比如所有 $y_i$ 都是 0,或者全部塌缩到一个点),我们需要加两个约束:
- 中心化约束:$\sum y_i = 0$(平移不变性,让低维数据的中心在原点)。
- 协方差约束:$\frac{1}{N} YY^T = I$(缩放不变性,防止数据无限缩小,保持单位方差)。
拉普拉斯特征映射(Laplacian Eigenmaps, LE)
LE 的核心思想是:若两点在高维空间中相似($W_{ij}$ 大),则它们在低维嵌入中应靠近。
拉普拉斯特征映射(简称LE)是基于图论的方法。它从样本点构造带权重的图,然后计算图的拉普拉斯矩,对该矩阵进行特征值分解得到投影变换矩阵。
一个示例无向图:
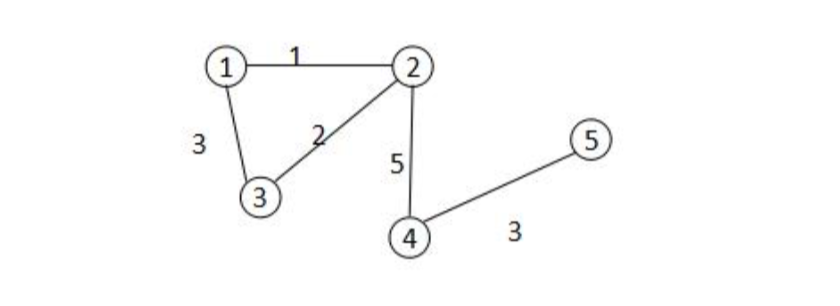
(请将此处的图片源替换为您的 image-4.png)
一个图所有节点之间的边的权重构成的矩阵称为邻接矩阵。假设 $i$ 和 $j$ 为图的顶点,$w_{ij}$ 为边 $(i, j)$ 的权重,由它构成的矩阵 $W$ 称为邻接矩阵。显然,无向图的邻接矩阵是一个对称矩阵。如果两个顶点之间没有边,则邻接矩阵的元素为 $0$。下面是上图中这个图的邻接矩阵:
$$ \begin{bmatrix} 0 & 1 & 3 & 0 & 0 \\ 1 & 0 & 2 & 5 & 0 \\ 3 & 2 & 0 & 0 & 0 \\ 0 & 5 & 0 & 0 & 3 \\ 0 & 0 & 0 & 3 & 0 \end{bmatrix} $$
节点的度定义为包含一个顶点的边的数量,对于有向图它还分为出度和入度,出度是指从一个顶点射出的边的数量,入度是连入一个节点的边的数量。由于边可以带有权重,因此可以定义带权重的度。定义节点 i 的带权重的度为与该节点相关的所有边的权重之和:
$$d_i = \sum_{j} w_{ij}$$
定义矩阵 D 为一个对角矩阵,其主对角线元素为每个顶点带权重的度:
$$ \begin{bmatrix} d_1 & \dots & 0 \\ \dots & \dots & \dots \\ 0 & \dots & d_n \end{bmatrix} $$
其中 $n$ 为图的顶点数。图的拉普拉斯矩阵定义为:
$L = D - W$
无向图的拉普拉斯矩阵是对称矩阵,另外可以证明它是半正定矩阵,因此所有特征值为非负实数。降维变换通过对拉普拉斯矩阵进行特征值分解得到。下面给出矩阵半正定的证明。对于任意的非 $0$ 向量 $f$,有:
$$ \begin{aligned} f^T L f &= f^T D f - f^T W f \\ &= \sum_{i=1}^n d_i f_i^2 - \sum_{i=1}^n \sum_{j=1}^n w_{ij} f_i f_j \\ &= \frac{1}{2} \left( \sum_{i=1}^n d_i f_i^2 - 2 \sum_{i=1}^n \sum_{j=1}^n w_{ij} f_i f_j + \sum_{j=1}^n d_j f_j^2 \right) \\ &= \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n w_{ij} (f_i - f_j)^2 \end{aligned} $$
因此拉普拉矩阵半正定。下面介绍通过拉普拉斯矩阵进行数据降维的具体做法。
假设有一批样本点 $x_1, \dots, x_k$,它们是 $R^l$ 空间的向量,降维的目标是将它们变换为更低维的 $R^m$ 空间中的向量 $y_1, \dots, y_k$,其中 $m \ll l$。在这里假设 $x_1, \dots, x_k \in M$,其中 $M$ 为嵌入 $R^l$ 空间中的一个流形。
算法为样本点构造加权图,图的节点是每一个样本点,边为每个节点与它的邻居节点之间的相似度,每个节点只和它的邻居有连接关系。
算法的第一步是构造图的邻接关系。如果样本点 $x_i$ 和样本点 $x_j$ 的距离很近,则为图的节点 $i$ 和节点 $j$ 建立一条边。判断两个样本点是否接近的方法有两种。第一种是计算二者的欧氏距离,如果距离小于某一值 $\varepsilon$ 则认为两个样本很接近:
$$ \|\mathbf{x}_i - \mathbf{x}_j\|^2 < \varepsilon $$
其中 $\varepsilon$ 是一个人工设定的阈值。第二种方法是使用近邻规则,如果节点 $i$ 在节点 $j$ 最近的 $n$ 个邻居节点的集合中,或者节点 $j$ 在节点 $i$ 最近的 $n$ 个邻居节点的集合中,则认为二者距离很近。
第二步是计算边的权重,在这里也有两种选择。第一种方法为如果节点 $i$ 和节点 $j$ 是联通的,则它们之间的边的权重为:
$$ w_{ij} = \exp \left( - \frac{\|\mathbf{x}_i - \mathbf{x}_j\|^2}{t} \right) $$
否则 $w_{ij} = 0$。其中 $t$ 是一个人工设定的大于 $0$ 的实数。第二种方式是如果节点 $i$ 和节点 $j$ 是联通的则它们之间的边的权重为 $1$,否则为 $0$。
$$Lf = \lambda Df$$
由于是实对称矩阵半正定矩阵,因此特征值非负。假设 $f_0, \ldots, f_{k-1}$ 是这个广义特征值问题的解,它们按照特征值的大小升序排列,即:
$$0 = \lambda_0 \leq \ldots \leq \lambda_{k-1}$$
- - 特征值 $\lambda$ 代表了“震荡频率”或者说“拉伸的能量”。
- - $\lambda$ 越小,说明这个映射越“平滑”,越能保留原本的局部关系。
- - $\lambda$ 很大,说明数据被拉扯得很剧烈,破坏了原本的结构。
去掉值为0的特征值 $\lambda_0$,用剩下部分特征向量为行来构造投影矩阵,将向量投影到以它们为基的空间中。
第三步理解
1. 核心思想:保持“近邻”
拉普拉斯特征映射的直观目标非常简单:如果两个点 $x_i$ 和 $x_j$ 在原空间很近(权重 $W_{ij}$ 很大),那么在低维空间里,它们的坐标 $f_i$ 和 $f_j$ 也必须很近。
用数学公式写出来,就是最小化下面这个目标函数:
$$\text{Target} = \sum_{i,j} W_{ij} (f_i - f_j)^2$$
如果 $W_{ij}$ 很大(两点关系密切),为了让总和变小,$(f_i - f_j)^2$ 必须很小(坐标必须靠近)。
如果 $W_{ij} = 0$(没关系),那么 $f_i$ 和 $f_j$ 离多远都无所谓。
2. 引入拉普拉斯矩阵 $L$
通过简单的代数推导(利用 $D$ 是度矩阵,$L = D - W$),上面的求和公式可以转化成漂亮的矩阵形式:
$$\sum_{i,j} W_{ij} (f_i - f_j)^2 = 2 f^T L f$$
这里:
- $W$:权重矩阵(图二算出来的)。
- $D$:度矩阵(对角矩阵,对角线上的值是 - $W$ 每一行的和,代表这个点的“重要性”)。
- $L$:拉普拉斯矩阵,定义为 $L = D - W$。
3. 约束条件与求解
我们要最小化 $f^T L f$。
但是,如果直接最小化,$f$ 全部等于 0 就最小了,但这没有意义。所以我们需要加一个约束条件,把数据“撑开”,通常固定其尺度:
$$f^T D f = 1$$
这是一个典型的广义瑞利商(Generalized Rayleigh Quotient)问题。利用拉格朗日乘子法,最小化 $f^T L f$ 且满足 $f^T D f = 1$ 的解,就是下面这个方程的解:
$$L f = \lambda D f$$
这就是图片中公式的由来!我们要求的坐标 $f$,就是这个方程的特征向量。
要去掉 $\lambda_0 = 0$图片里特别提到:“去掉值为 0 的特征值 $\lambda_0$”。这是初学者最容易困惑的地方。
$\lambda_0 = 0$ 对应的解是什么?
对应的是一个“全 1 向量” $f = [1, 1, 1, ..., 1]^T$。
把这个代入公式,你会发现 $Lf = 0$ 恒成立。
这代表什么意思?
这代表把所有的点都映射到同一个位置(比如大家都重叠在坐标 1 上)。
在这种情况下,所有点距离为 0,能量确实最小(不仅是最小,直接是 0 了)。
但这对于数据分析毫无意义!把所有数据降维成一个点,我们还分析什么呢?
所以怎么办?
我们要找“能量第二小”的解。
$\lambda_0$ (最小):所有人缩成一个点(无意义,扔掉)。
$\lambda_1$ (第二小):这是真正有意义的、能把数据稍微拉开一点、但又保持紧密关系的这种解。
$\lambda_2$ (第三小):另一个维度的解。